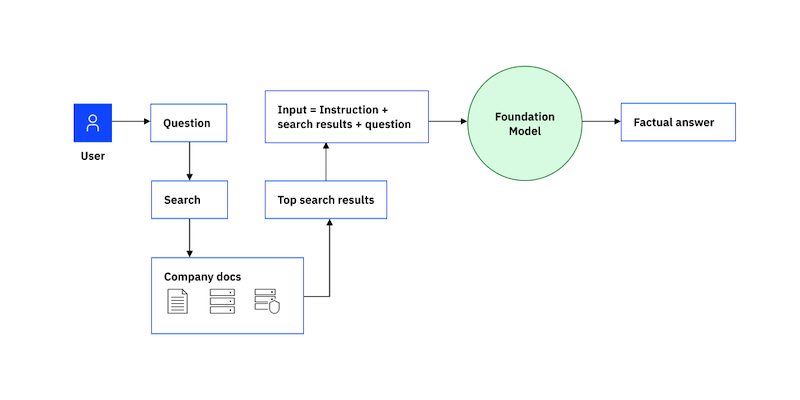
Upon coping with LLM generative linguistic capabilities and prompt engineering, one of the main challenges to be tackled is the risk of hallucinations. In the fouth quarter 2023 a new approach to fight and reduce them in LLM outcomes was tested and published by a group of researchers from Meta AI: Chain-of-Verification (CoVe).
What these researchers aimed at was to prove the ability of language models to deliberate on the responses they give in order to correct their mistakes. In the Chain-of-Verification (CoVe) method the model first drafts an initial response; then plans verification questions to fact-check its draft; subsequently answers those questions independently so that the answers are not biased by other responses; and eventually generates its verified improved response.
Setting up the stage
Large Language Models (LLMs) are trained on huge corpora of text documents with billions of tokens of text. It has been shown that as the number of model parameters is increased, performance improve in accuracy, and larger models can generate more correct factual statements.
However, even the largest models can still fail, particularly on lesser known long-tailed distribution facts; i.e. those that occur relatively rarely in the training corpora. In those cases where the model is incorrect, they instead generate an alternative response which is typically plausible looking, but an incorrect one: a hallucination.
The current wave of language modeling research goes beyond next word prediction, and has focused on their ability to reason. Improved performance in reasoning tasks can be gained by encouraging language models to first generate internal thoughts or reasoning chains before responding, as well as updating their initial response through self-critique. This is the line of research followed by the Chain-of-Verification (CoVe) method: given an initial draft response, firstly it plans verification questions to check its work, and then systematically answers those questions in order to finally produce an improved revised response.
The Chain-of-Verification Approach
This approach assumes access to a base LLM that is capable of being prompted with general instructions in either a few-shot or zero-shot fashion. A key assumption in this method is that this language model, when suitably prompted, can both generate and execute a plan of how to verify itself in order to check its own work, and finally incorporate this analysis into an improved response.
The process entails four core steps:
1. Generate Baseline Response: Given a query, generate the response using the LLM.
2. Plan Verifications: Given both query and baseline response, generate a list of verification questions that could help to self-analyze if there are any mistakes in the original response.
3. Execute Verifications: Answer each verification question in turn, and hence check the answer against the original response to check for inconsistencies or mistakes.
4. Generate Final Verified Response: Given the discovered inconsistencies (if any), generate a revised response incorporating the verification results.
Conditioned on the original query and the baseline response, the model is prompted to generate a series of verification questions that test the factual claims in the original baseline response. For example, if response may contains the statement “The Mexican–American War was an armed conflict between the United States and Mexico from 1846 to 1848”, then one possible verification question to check those dates could be “When did the Mexican American war start and end?” It is important to highlight that verification questions are not templated and the language model is free to phrase these in any form it wants and they also do not have to closely match the phrasing of the original text.
Given the planned verification questions, the next step is to answer them in order to assess if any hallucinations exist: the model is used to check its own work. In their paper, the Meta AI researchers investigated several variants of verification execution: Joint, 2-Step, Factored and Factor+Revise.
Joint: In the Joint method, the afore-mentioned planning and execution steps (2 and 3) are accomplished by using a single LLM prompt, whereby the few-shot demonstrations include both verification questions and their answers immediately after the questions.
2-Step: in this method, there is a first step in which verification prompts are generated and then these verification questions are answered in a second step, where crucially the context given to the LLM prompt only contains the questions, and not the original baseline response and hence cannot repeat those answers directly.
Factored: this method consists of answering all questions independently as separate prompts. those prompts do not contain the original baseline response and are hence not prone to simply copying or repeating it.
Factor+Revise: in this method, after answering the verification questions, the overall CoVe pipeline then has to either implicitly or explicitly cross-check whether those answers indicate an inconsistency with the original responses. For example, if the original baseline response contained the phrase “It followed in the wake of the 1845 U.S. annexation of Texas. . . ” and CoVe generated a verification question such as “When did Texas secede from Mexico?”, which would be answered with 1836 then an inconsistency should be detected by this step.
And in the final part of this four-step process, the improved response that takes verification into account is generated. This is executed through taking into account all of the previous reasoning steps -the baseline response and verification question answer pairs-, so that the corrections can happen.
As a conclusion, Chain-of-Verification (CoVe) is an approach to reduce hallucinations in a large language model by deliberating on its own responses and self-correcting them. LLMs are able to answer verification questions with higher accuracy than when answering the original query, by breaking down the verification into a set of simpler questions. And besides, when answering the set of verification questions, controlling the attention of the model so that it cannot attend to its previous answers (factored CoVe) helps alleviate copying the same hallucinations.
Stated the above, CoVe does not remove hallucinations completely from the generated outcomes. While this approach gives clear improvements, the upper bound to the improvement is limited by the overall capabilities of the model, e.g. in identifying and knowing what it knows. In this regard, the use of external tools by language models -for instance,RAG,-to gain further information beyond what is stored in its weights- would grant very likely promising results.
Eventually and some months after its presentation at the Geneva Centre for Security Policy, I have had the chance of diving into the book “The AI Wave in Defense Innovation. Assessing Military Artificial Intelligence Strategies, Capabilities, and Trajectories.” Edited by Michael Raska and Richard A. Bitzinger and with the contribution from experts in different fields -AI, intelligence, technology governance, defense innovation…-, this volume is an international and interdisciplinary perspective on the adoption and governance of AI in defense and military innovation by major and middle powers.
From the different chapters, I deem it should be stressed the one titled “AI Ethics and Governance in Defense Innovation. Implementing AI Ethics Framework” by Cansu Canca, owing to the meaningful insights included in it.
For the author, AI use within a military context raises various ethical concerns due to high ethical risks often inherent in these technologies. A comprehensive account of the ethical landscape of AI in the military must also account for the potential ethical benefits. AI ethics within a military context is hence a double-edged sword. To illustrate this dual aspect, Canca lists some ethical pairs of pros and cons:
Precision vs. Aggression
A major area of AI applications for the military is about increasing precision -the Pentagon-funded Project Maven is probable the best example of this.
The military benefits of increased precision in surveillance and potentially in targeting are clear. AI may help search and rescue mission, predict and prevent deadly attacks from the opponent, and eliminate or decrease errors in defense. However, these increased capabilities might also boost the confidence of armed forces and make them more aggressive in their offensive and defensive attacks, resulting in more armed conflicts and more casualties.
Efficiency vs. Lowered Barriers to Conflict
AI systems that reduce the need for human resources, keep humans safe, and allow human officers to use their expertise are beneficial for the military and military personnel. The other side of the coin is the concern that increasing efficiency and safety for the military will also lower the barriers to entering a conflict: if war is both safe and low cost, what would stand in the way of starting one?
Those who lack the technology would be deterred from starting a war, whereas those equipped with the technology could become even more eager to escalate a conflict.
Protecting combatants vs. Neglecting Responsibility and Humanity
Sparing military personnel’s lives and keeping them safe from death and physical and mental harm would be a clear benefit for the military. However, it is never that simple: Can an officer remotely operating a weapon feel the weight of responsibility of “pulling the trigger” as strongly when they are distant from the “other”? Can they view the “other” as possessing humanity, when they are no longer face-to-face with them?
The ethical decision-making of a human is inevitably intertwined with human psychology. How combatants feel about the situation and the other parties necessarily feature in their ethical reasoning. The question is: where, if anywhere, should we draw the line on the spectrum of automation and remote control to ensure that human officers still engage in ethical decision-making, acknowledging the weight of their decisions and responsibility as they operate and collaborate with AI tools?
Military use of AI is not good or bad; it is a mixed bag. For that reason, more than ever it is needed the creation and implementation of frameworks for the ethical design, development, and deployment of AI systems.
AI Ethics Framework
AI ethics has increasingly been a core area of concern across sectors, particularly since 2017, when technology-related scandals slowly started to catch the public’s attention. AI ethics is concerned with the whole AI development and deployment cycle. This includes research, development, design, deployment, use, and even the updating stages of the AI life cycle.
Each stage presents its unique ethical questions, being some of them:
Does the dataset represente the world and, if not, who is left out?
Does the algorithm prioritize a value explicitly or implicitly? And if it does, is this justified?
Does the dashboard provide information for a user to understand the core variables of an AI decision-aid tool?
Did research subjects consent to have their data used?
Do professional such as military officers, managers, physicians, and administrators understand the limitation of the AI tools they are handed?
As users engage with AI tools in their professional or personal daily lives, do they agree to have their data collected and used, and do they understand its risks?
What makes ethical issues AI-specific are the extremely short gap between R&D and practice, the wide-scale and systematic use of AI systems, the increased capabilities of AI systems, and the façade of computational objectivity. Concerning the latter, this point is extremely dangerous because it allows users -such as judges and officers- to put aside their critical approach and prevents them from questioning the system’s results. Inadvertently the AI system leads them to make ethical errors and do so systematically due to their over-reliance on the AI tool.
The ethical questions and issues that AI raises cannot be addressed through this traditional ethics compliance and oversight model. Neither can they be solved solely through regulation. Instead, and according to the author, we need a comprehensive AI ethics framework to address all aspects of AI innovation and use in organizations. A proper AI ethics strategy consists of the playbook component, which includes all ethical guiding materials such as ethics principles, use cases, and tools; the process component, which includes ethics analysis and ethics-by-design components, and structures how and when to integrate these and other ethics components into the organizational operations; and the people component, which structures a network of different ethics roles within the organization.
AI Ethics Playbook
The AI ethics playbook forms the backbone of the AI ethics strategy, consisting of all guidelines and tools to aid ethical decision-making at all levels; i.e., fundamental principles to create a solid basis, accesible and user-friendly tools that help apply these principles, and use cases that demonstrate how to use these tools and bring the principles into action. The AI ethics playbook should be a living document.
As an example, these are the AI ethics principles recommended by the US Department of Defense in 2019:
Responsibility: DoD personnel will exercise appropriate levels of judgement and care concerning the development, deployment, and use of AI capabilities.
Equitability: The DoD will take the required steps to minimize unintended bias in AI capabilities.
Traceability: DoD relevant personnel must possess an appropriate understanding of the technology, development processes, and operational methods applicable to AI capabilities.
Reliability: the safety, security, and effectiveness of AI capabilities will be subject to testing and assurance.
Governability: DoD will design AI capabilities to fulfill their intended functions while processing the ability to detect and avoid unintended consequences, and the ability to disengage or deactivate deployed systems that demonstrate unintended behavior.
AI Ethics Process
AI playbook is inconsequential if there is no process to integrate it into the organization’s operations. Therefore an essential part of an AI ethics strategy is figuring out how to add the playbook into the organization’s various operations seamlessly. The objective of the AI ethics process is to create systematic procedures for ethics decisions which include: structuring the workflow to add “ethics checkpoints”; ethics analysis and ethics-by-design sessions; documenting ethics decisions and adding them into the playbook as use cases; and finally ensuring a feedback loop between new decisions and the updating of the playbook when needed.
AI Ethics People
A network of people who carry different roles concerning ethics should be embedded into every layer of the organization. It should be clear from the tasks at hand that the ethics team’s work is distinct from the legal team. Whilst there should be close collaboration between legal and ethics experts, the focus of legal experts and their skills and tools differ significantly from those of ethics experts.
And last but not least, from Canca’s standpoint, an ethics framework without an accountability mechanism would be limited to individuals’ motivation to “do good” rather than functioning as a reliable and strategic organizational tool. To that end, an AI ethics framework should be supported by AI regulations. AI regulations would function as an external enforcing mechanism to define the boundaries of legally acceptable action and to establish a fair playing field for competition. Regulations should also function to support the AI ethics framework by requiring basic components of this framework to be implemented such as an audit mechanism for the safety, reliability, and fairness of AI systems. Having such a regulatory framework for AI ethics governance would also help create citizen trust.
In 2020 Meta (then known as Facebook) published the paper Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, which came up with a framework called retrieval-augmented generation (RAG) to give LLMs access to information beyond their training data.
Large language models can be inconsistent. Sometimes they can grant a perfect answer to a question, but other times they regurgitate aleatory facts from their training data.
Retrieval-augmented generation (RAG) is a technique for enhancing the accuracy and reliability of generative AI models with facts fetched from external sources. In other words, it fills a gap in how LLMs work. Under the hood, LLMs are neural networks, typically measured by how many parameters they contain. An LLM’s parameters essentially represent the general patterns of how humans use words to form sentences. That deep understanding makes LLMs useful in responding to general prompts extremely fast. Nonetheless, it does not serve users who want a deeper dive into a current or more specific topic. Retrieval-augmented generation (RAG) gives models sources they can cite, so users can check any claims. That builds trust. What’s more, the technique can help models clear up ambiguity in a user query.
The roots of the technique go back at least to the early 1970s. That’s when researchers in information retrieval (IR) prototyped what they called question-answering systems, apps that use natural language processing to access text initially in narrow topics.
Implementing RAG in an LLM-based question answering system has two main benefits: It ensures that the model has access to the most current, reliable facts, and that users have access to the model’s sources, ensuring that the accuracy of responses can be easily checked.
By grounding an LLM on a set of external, verifiable facts, the model has fewer opportunities to “hallucinate” or mislead information. RAG allows LLMs to build on a specialized body of knowledge to answer questions in more accurate way. It also reduces the need for users to continuously train the model on new data and update its parameters, as circumstances evolve. In this way, RAG can lower the computational and financial costs of running LLM-powered chatbots in an enterprise setting.
RAG has two phases: retrieval and content generation. In the retrieval phase, algorithms search for and retrieve snippets of information relevant to the user’s prompt or question. In an open-domain, consumer setting, those facts can come from indexed documents on the internet; in a closed-domain, enterprise setting, a narrower set of sources are typically used for added security and reliability.
This collection of outside information is sent to the language model along with the user’s request. During the generative phase, the LLM creates an appealing answer that is customized for the user currently using the enhanced prompt and its internal representation of its training data. A chatbot can then be given the response together with connections to its original sources. The entire procedure can be represented graphically as follows:
Summing up, customer queries are not always straightforward. They can be ambiguously worded, complex, or require knowledge the model either doesn’t have or can’t easily parse. These are the conditions in which LLMs are prone to making things up. LLMs need to be explicitly trained to recognize questions they can’t answer, it may need though to see thousands of examples of questions that can and can’t be answered. Only then can the model learn to identify an unanswerable question, and probe for more detail until it hits on a question that it has the information to answer. RAG is currently the best-known tool for grounding LLMs on the latest, verifiable information, and it allows LLMs to go one step further by greatly reducing the need to feed and retrain the model on fresh examples.
For much time it seemed that in the computing landscape the main application of graphs were only related to ontology engineering, so when my colleague Mihael shared with me the paper “Graph of Thoughts: Solving Elaborate Problems with Large Language Models” -published by the end of August-, I thought we might be in the right path to re-discover the power to representing knowledge of these structures. In the afore-mentioned paper, the authors harness the graph abstraction as a key mechanism that enhances prompting capabilities in LLMs.
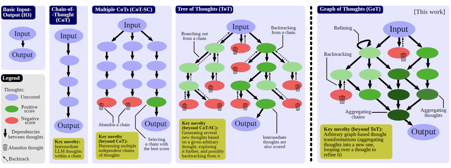
Prompt engineering is one of the central new domains of the large language model research. However, designing effective prompts is a challenging task. Graph of Thoughts (GoT) is a new paradigm that enables the LLM to solve different tasks effectively without any model updates.The key idea is to model the LLM reasoning as a graph, where thoughts are vertices and dependencies between thoughts are edges.
Human’s task solving is often non-linear, and it involves combining intermediate solutions into final ones, or changing the flow of reasoning upon discovering new in sights. For example, a person could explore a certain chain of reasoning, backtrack and start a new one, then realize that a certain idea from the previous chain could be combined with the currently explored one, and merge them both into a new solution, taking advantage of their strengths and eliminating their weaknesses. GoT reflects this, so to say, anarchic reason process with its graph structure.
Nonetheless, let’s take a step back: besides Graph of Thoughts, there are other approaches for prompting:
Input-Output (IO): a straightforward approach in which we use an LLM to turn an input sequence x into the output y directly, without any intermediate thoughts.
Chain-of-Thought (CoT): one introduces intermediate thoughts a1, a2,… between x and y. This strategy was shown to significantly enhance various LLM tasks over the plain IO baseline, such as mathematical puzzles or general mathematical reasoning.
Multiple CoTs: generating several (independent) k CoTs, and returning the one with the best output, according to certain metrics.
Tree of Thoughts (ToT): it enhances Multiple CoTs by modeling the process of reasoning as a tree of thoughts. A single tree node represents a partial solution. Based on a given node, the thought generator constructs a given number k of new nodes. Then, the state evaluator generates scores for each such new node.
Explained in a more visual way:
Image taken from the paper “Graph of Thoughts: Solving Elaborate Problems with Large Language Models”
The design and implementation of GoT, according to the authors, consists of four main components: the Prompter, the Parser, the Graph Reasoning Schedule (GRS), and the Thought Transformer:
The Prompter prepares the prompt to be sent to the LLM, using a use-case specific graph encoding.
The Parser extracts information from the LLM’s thoughts, and updates the graph structure accordingly.
The GRS specifies the graph decomposition of a given task, i.e., it prescribes the transformations to be applied to LLM thoughts, together with their order and dependencies.
The Thought Transformer applies the transformations to the graph, such as aggregation, generation, refinement, or backtracking.
Finally, the authors evaluate GoT on four use cases -sorting, keyword counting, set operations, and document merging-, and compare it to other prompting schemes in terms of quality, cost, latency, and volume. The authors show that GoT outperforms other schemes, especially for tasks that can be naturally decomposed into smaller subtasks, are solved individually, and then merged for a final solution.
Summing up, another breath of fresh air in this hecticly evolving world of AI; this time combining abstract reasoning, linguistics, and computer sciences. Pas mal at all.
Much has been stated about the impact of Generative AI on the workforce for the past months, and many more pages will be written in the coming ones.
Last September, 15th 2023, appeared the paper “Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of AI on KnowledgeWorker Productivity and Quality” by, amongst others, Harvard Business School and MIT Sloan School of Management. Some months in advance -in June- McKinsey & Company published a meaningful report titled “The Economic Potential of Generative AI”
Some of the thoughts exposed in them are worthy to be pondered.
The paper by Harvard Business School and MIT Sloan School of Management examined the performance implications of AI on complex knowledge-intensive tasks, using controlled field experiments with highly skilled professionals. The experiments involved two sets of tasks: one inside and one outside the potential technological frontier of GPT-4, OpenAI large language model. The participants were randomly assigned to one of three experimental conditions: no AI, AI only, or AI plus overview. The “overview condition” provided participants with additional materials that explained the strengths and limitations of GPT-4, as well as effective usage strategies.
Understanding the implications of LLMs for the work of organizations and individuals has taken on urgency among scholars, workers, companies, and even governments. Outside of their technical differences from previous forms of machine learning, there are three aspects of LLMs that suggest they will have a much more rapid, and widespread impact on work.
The first is that LLMs have surprising capabilities that they were not specifically created to have, and ones that are growing rapidly over time as model size and quality improve. Trained as general models, LLMs nonetheless demonstrate specialist knowledge and abilities as part of their training process and during normal use.
The general ability of LLMs to solve domain-specific problems leads to the second differentiating factor of LLMs compared to previous approaches to AI: their ability to directly increase the performance of workers who use these systems, without the need for substantial organizational or technological investment. Early studies of the new generation of LLMs suggest direct performance increases from using AI, especially for writing tasks and programming, as well as for ideation and creative work. As a result, the effects of AI are expected to be higher on the most creative, highly paid, and highly educated workers.
The final relevant characteristic of LLMs is their relative opacity. The advantages of AI, while substantial, are similarly unclear to users. It performs well at some jobs, and fails in other circumstances in ways that are difficult to predict in advance.
Taken together, these three factors suggest that currently the value and downsides of AI may be difficult for workers and organizations to grasp. Some unexpected tasks (like idea generation) are easy for AI, while other tasks that seem to be easy for machines to do (like basic math) are challenges for some LLMs. This creates an uneven blurred frontier, in which tasks that appear to be of similar difficulty may either be performed better or worse by humans using AI.
The future of understanding how AI impacts work involves understanding how human interaction with AI changes depending on where tasks are placed on this frontier, and how the frontier will change over time. The current generation of LLMs are highly capable of causing significant increases in quality and productivity, or even completely automating some tasks, but the actual tasks that AI can do are surprising and not immediately obvious to individuals or even to producers of LLMs themselves, because this frontier is expanding and changing. According to the research performed, on tasks within the frontier AI significantly improved human performance. Outside of it, humans relied too much on the AI and were more likely to make mistakes. Not all users navigated the uneven frontier with equal adeptness. Understanding the characteristics and behaviors of these participants may prove important, as organizations think about ways to identify and develop talent for effective collaboration with AI tools.
Two predominant models that encapsulate human approach to AI could be identified, according to the Harvard and MIT research. The first is Centaur behavior: this approach involves a similar strategic division of labor between humans and machines closely fused together. Users with this strategy switch between AI and human tasks, allocating responsibilities based on the strengths and capabilities of each entity. They discern which tasks are best suited for human intervention and which can be efficiently managed by AI. The second approach is Cyborg behavior. In this stance users don’t just delegate tasks; they intertwine their efforts with AI at the very frontier of capabilities.
Upon identifying tasks outside the frontier, performance decreases were observed as a result of AI. Professionals who had a negative performance when using AI tended to blindly adopt its output and interrogate it less. Navigating the frontier requires expertise, which will need to be built through formal education, on-the-job training, and employee-driven up-skilling. Moreover, the optimal AI strategy might vary based on a company’s production function. While some organizations might prioritize consistently high average outputs, others might value maximum exploration and innovation.
Overall, AI seems poised to significantly impact human cognition and problem-solving ability. Similarly to how the internet and web browsers dramatically reduced the marginal cost of information sharing, AI may also be lowering the costs associated with human thinking and reasoning.
The era of generative AI is just beginning. Excitement over this technology is palpable, and earlypilots are compelling. It is extremely complex to forecast the adoption curves of this technology. According to historical findings, technologies take 8 to 27 years from commercial availability to reach a plateau in adoption. Some argue that the adoption of generative AI will be faster due to the ease of deployment. For McKinsey, it will be needed a minimum of eight years -in its earliest scenario- for reaching a global plateau in adoption.
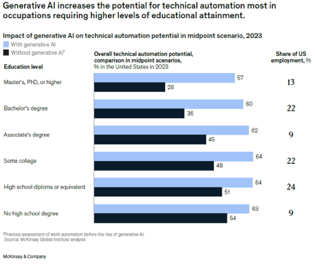
One final note about the labor impact of GenAI: economists have often noted that the deployment of automation technologies tends to have the most impact on workers with the lowest skill levels -as measured by educational attainment-, or what is called skill biased. From the McKinsey analysis, we can reach the conclusion that generative AI has the opposite pattern—it is likely to have the most incremental impact through automating some of the activities of more-educated workers:
Notwithstanding, a full realization of the technology’s benefits will take time, and leaders in business and society still have considerable challenges to address. These include managing the risks inherent in generativeAI, determining what new skills and capabilities the workforce will need, and rethinking core business processes such as retraining and developing new skills.