Some days ago and for my PhD research, I finished reading some papers about AI, disinformation, and intrinsic biases in LLMs, and “all this music” sounded familiar. It reminded to me a book I read some years ago by Thomas Rid, “Active Measures: The Secret History of Disinformation and Political Warfare”… As it was written in the Vulgate translation of Ecclesiastes: “Nihil sub sole novum.“
Let’s tackle briefly these topics of national security and disinformation from the angle of the (Gen)AI.
On National Security
The overwhelming success of GPT-4 in early 2023 highlighted the transformative potential of large language models (LLMs) across various sectors, including national security. LLMs have the capability to revolutionize the efficiency of this realm. The potential benefits are substantial: LLMs can automate and accelerate information processing, enhance decision-making through advanced data analysis, and reduce bureaucratic inefficiencies. Their integration with probabilistic, statistical, and machine learning methods can improve as well accuracy and reliability: upon combining LLMs with Bayesian techniques, for instance, we could generate more robust threat predictions with less manpower.
Said that, deploying LLMs into national security organizations does not come without risks. More specifically, the potential for hallucinations, the ensuring of data privacy, and the safeguarding of LLMs against adversarial attacks are significant concerns that must be addressed.
In the USA and at domestic level, the Central Intelligence Agency (CIA) began exploring generative AI and LLM applications more than three years before the widespread popularity of ChatGPT. Generative AI was leveraged in a 2019 CIA operation called Sable Spear to help identify entities involved in illicit Chinese fentanyl trafficking. The CIA has since used generative AI to summarize evidence for potential criminal cases, predict geopolitical events such as Russia’s invasion of Ukraine, and track North Korean missile launches and Chinese space operations. In fact, Osiris, a generative AI tool developed by the CIA, is currently employed by thousands of analysts across all eighteen U.S. intelligence agencies. Osiris operates on open-source data to generate annotated summaries and provide detailed responses to analyst queries. The CIA continues to explore LLM incorporation in their mission sets and recently adopted Microsoft’s generative AI model to analyze vast amounts of sensitive data within an air-gapped, cloud-based environment to enhance data security and accelerate the analysis process.
Following with the USA but in an international level, the United States and Australia are leveraging generative AI for strategic advantage in the Indo-Pacific, focusing on applications such as enhancing military decision-making, processing sonar data, and augmenting operations across vast distances.
USA’s strategic competitors -e.g., China, Russia, North Korea, and Iran- are also exploring the national security applications of LLMs. For example, China employs Baidu’s Erni Bot, an LLM similar to ChatGPT, to predict human behavior on the battlefield to enhance combat simulations and decision-making.
These examples demonstrate the transformative potential of LLMs on modern military and intelligence operations. Nonetheless, beyond immediate defense applications, LLMs have the potential to influence strategic planning, international relations, and the broader geopolitical landscape. The purported ability of nations to leverage LLMs for disinformation campaigns emphasizes the need to develop appropriate countermeasures and continuously scrutinize and update (Gen)AI security protocols.
On Disinformation
What if LLMs already had their own ideological bias that turned them into tools of disinformation rather than tools of information?
It seems the times of search engine as information oracles is over. Large Language Models (LLMs) have rapidly become knowledge gatekeepers. LLMs are trained on vast amounts of data to generate natural language; however, the behavior of LLMs varies depending on their design, training, and use.
As exposed by Maarten Buyl et alii in their paper “Large Language Model Reflect the Ideology of their Creators”, there is notable diversity in the ideological stance exhibited across different LLMs and languages in which they are accessed; for instance, there are consistent differences between how the same LLM responds in Chinese compared to English. Similarly, there are normative disagreements between Western and non-Western LLMs about prominent actors in geopolitical conflicts. The ideological stance of an LLM often reflects the worldview of its creators. This raises important concerns around technological and regulatory efforts with the stated aim of making LLMs ideologically ‘unbiased’, and indeed it poses risks for political instrumentalization. Although the intention of LLM creators as well as regulators may be to ensure maximal neutrality, such high goal may be fundamentally impossible to achieve… unintentionally or fully intentionally.
After analyzing the performance of seventeen LLMs, the authors exposed the following findings:
The ideology of an LLM varies with the prompting language: The language in which an LLM is prompted is the most visually apparent factor associated with its ideological position.
Political people clearly adversarial towards mainland China, such as Jimmy Lai or Nathan Law, received significantly higher ratings from English-prompted LLMS compared to Chinese-prompted LLMs.
Conversely, political people aligned with mainland China, such as Yang Shangkun, Anna Louise Strong, o Deng Xiaoping, are rated more favorably by Chinese-prompted LLMs. Additionally, some communist/marxist political people, including Ernst Thälmann, Che Guevara, or Georgi Dimitrov, received higher ratings in Chinese.
LLMs, responding in Chinese, demonstrated more favorable attitudes toward state-led economic systems and educational policies, align with the priorities of economic development, infrastructure investment, and education, which are key pillars of China’s political and economic agenda.
These differences reveal language-dependent cultural and ideological priorities embedded in the models.
Another question the authors addressed was whether there was substantial ideological variation between models when prompted in the same language -specifically English-, and created in the same cultural region -i.e., the West. Within the group of Western LLMs, an ideological spectrum also emerges. For instance and amongst others:
The OpenAI models exhibit a significantly more critical stance toward supranational organizations and welfare policies.
Gemini-Pro shows a stronger preference for social justice, diversity, and inclusion.
Mistral shows a stronger support for state-oriented and cultural values.
The Anthropic model focuses on centralized governance and law enforcement.
These results suggest that ideological standpoints are not merely the result of different ideological stances in the training corpora that are available in different languages, but also of different design choices. These design choices may include the selection criteria for texts included in the training corpus or the methods used for model alignment, such as fine-tuning and reinforcement learning with human feedback.
Summing up, the two main takeaways concerning disinformation and LLMs are the following:
Firstly, the choice of LLM is not value-neutral, specifically when one or a few LLMs are dominant in a particular linguistic, geographic, or demographic segment of society, this may ultimately result in a shift of the ideological center of gravity.
Secondly, the regulatory attempts to enforce some form of ‘neutrality’ onto LLMs should be critically assessed. Instead, initiatives at regulating LLMs may focus on enforcing transparency about design choices, which may impact the ideological stances of LLMs.
As mentioned in our post “China: Techno-socialism Seasoned with Artificial Intelligence“, in its aim of gaining a global leadership role, China launched the Belt and Road Initiative in 2013: a global infrastructure development strategy to invest in more than 150 countries and international organizations. The BRI was composed of six urban development land corridors linked by road, rail, energy, and digital infrastructure and the Maritime Silk Road, linked by the development of ports.
In 2015, the Chinese government published the “Vision and Actions on Jointly Building Silk Road Economic Belt and 21st Century Maritime Silk Road”, introducing the concept of “Information Silk Road” as a component of BRI -later to be rebranded as “digital’ to encompass its broader aspirations. In 2017, during the BRI Forum in Beijing, Xi Jinping stated the use of AI and big data would be incorporated in the future of BRI as well, further illustrating its broad and ever-evolving nature. The DSR is an important component of China’s Belt and Road Initiative (BRI); it covers a wide array of areas, ranging from telecommunications networks, to ‘Smart City’ projects, to e-commerce, to Chinese satellite navigation systems, and of course AI.
The DSR aims at the global expansion of Chinese technologies to markets in which western players have previously dominated, or in developing countries that are only now undergoing a technological revolution. The implementation of China’s DSR has mainly covered the developing countries of Africa, Asia, Latin America, the Middle East, and Eastern Europe. China presents the DSR as a tool for development, innovation, and technological evolution. However, in its ambitions and impact, the DSR is also a question of geopolitics, as it facilitates China’s attempt to establish itself as a major global power across a growing number of technical and research fields, and regions.
With the growing prominence of the DSR, some Western countries have voiced their concerns about the potential risks related to Chinese technology and involvement in sensitive sectors. Both the US and EU have taken steps to counter the rising influence of the DSR. As a tool to contest the Chinese initiative, the US launched the ‘Clean Network’ initiative. Said that, the EU does not have a unified stance on cooperation with China on the DSR. Among 27 members, there are ‘champions’ of the pushback against China, especially among Central and Eastern European countries like Czechia, Slovakia, Slovenia, and Romania, that have aligned with the US’ initiative. Others, like France, have not introduced outright bans but have de facto decided to exclude “untrusted vendors”, and to focus on the European companies and equipment due to security concerns. Germany, on the contrary, is still considering the inclusion of the Chinese companies in the construction of its 5G infrastructure, for instance.
Western Balkans is a region that has been often seen as a springboard by China regarding its presence in Europe. Chinese efforts to include Serbia in the DSR have been more than welcomed and hence Serbia has become a main stop for the Chinese initiative in the region.
Serbia has developed extensive and strategic relations with China over the past decade. The partnership has also included cooperation within the framework of the DSR. Serbia and China signed the Strategic Agreement on Economic, Technological, and Infrastructural cooperation in 2009. That agreement was a starting point for the development of the contemporary relations between two countries and a cornerstone for future joint projects. During the visit of Chinese leader Xi Jinping to Belgrade in 2016, the two countries established a Comprehensive Strategic Partnership.
DSR has reached Serbia and made it the focal point in the Western Balkans. However, cooperation could come with a price. If Serbia relies too much on China in its technological development and does not differentiate partner companies and suppliers, it may become too dependent on its Chinese partners. The absence of diversification can jeopardize the sustainability of the system and the possibility of further improvements of the system in the future. The need of not being dependent on foreign technology is a lesson perfectly learned and practiced by the Chinese authorities concerning AI.
Chinese Non-dependency Policy Regarding GenAI / LLMs
For China and Chinese companies, developing indigenous LLMs is a matter of independence from foreign technologies and also a matter of national pride. Since August 2023, when China’s rules on generative AI came into effect, 46 different LLMs developed by 44 different companies were approved by the authorities. The legislation requires companies to ensure that the models’ responses align with the communist values and also undergo a security self-assessment, which has, however, not been defined until recently. Besides the afore-mentioned approved models, it is estimated that there are more than 200 different LLMs currently functioning in China.
The first wave of models approved in August 2023 was predominantly general LLM models developed by the biggest players in China’s technological market – Baidu, Tencent, Alibaba, Huawei, iFlytek, SenseTime, and ByteDance. Besides these companies, Chinese research institutions, namely the Chinese Academy of Sciences and Shanghai Artificial Intelligence Laboratory, received approvals for their models. In the following batches, models with specific applications started to appear: models designed for recruitment purposes -ranging from CV formatting to providing recommendations; models designed to help companies with cyber security assessments and risk prevention; models designed for readers to interact with their favorite literary characters; models aimed at video content generation based on an article or an idea description; and models providing recommendations to customers and serve as AI assistants.
In March 2024, China’s National Information Security Standardization Technical Committee (TC260) published its basic security requirements for generative AI, which qualifies as a technical document providing detailed guidance for authorities and providers of AI services. This text sets measures regarding the security of training data. Providers must randomly choose 4,000 data points from each training corpus and the number of ‘illegal’ or ‘harmful’ information should not exceed five percent. Otherwise, the corpus may not be used for training. Developers are also required to maintain information about the sources of the training data and the collection processes, and acquire agreement or other authorization to use data for training when using open-source data. This document also provides detailed guidance regarding the evaluation of the model’s responses. Providers are required to create a 2,000-question bank designed to control the model’s outputs in the case of areas defined as “security risks.” -everything which might mean a violation or threat to the communist values.
Importantly and as final note concerning the willingness of being independent from foreign technical developments, the newest AI rules stipulate that Chinese companies are not allowed to use unregistered third-party foundation models to provide public services. This means that access to LLMs developed outside China becomes even more limited and some of the Chinese AI companies who have built their applications based on ChatGPT or LlaMa, for instance, will need to find other solutions.
More than ever the geopolitical battlefield is played mainly on the technological / AI realm.
Upon coping with LLM generative linguistic capabilities and prompt engineering, one of the main challenges to be tackled is the risk of hallucinations. In the fouth quarter 2023 a new approach to fight and reduce them in LLM outcomes was tested and published by a group of researchers from Meta AI: Chain-of-Verification (CoVe).
What these researchers aimed at was to prove the ability of language models to deliberate on the responses they give in order to correct their mistakes. In the Chain-of-Verification (CoVe) method the model first drafts an initial response; then plans verification questions to fact-check its draft; subsequently answers those questions independently so that the answers are not biased by other responses; and eventually generates its verified improved response.
Setting up the stage
Large Language Models (LLMs) are trained on huge corpora of text documents with billions of tokens of text. It has been shown that as the number of model parameters is increased, performance improve in accuracy, and larger models can generate more correct factual statements.
However, even the largest models can still fail, particularly on lesser known long-tailed distribution facts; i.e. those that occur relatively rarely in the training corpora. In those cases where the model is incorrect, they instead generate an alternative response which is typically plausible looking, but an incorrect one: a hallucination.
The current wave of language modeling research goes beyond next word prediction, and has focused on their ability to reason. Improved performance in reasoning tasks can be gained by encouraging language models to first generate internal thoughts or reasoning chains before responding, as well as updating their initial response through self-critique. This is the line of research followed by the Chain-of-Verification (CoVe) method: given an initial draft response, firstly it plans verification questions to check its work, and then systematically answers those questions in order to finally produce an improved revised response.
The Chain-of-Verification Approach
This approach assumes access to a base LLM that is capable of being prompted with general instructions in either a few-shot or zero-shot fashion. A key assumption in this method is that this language model, when suitably prompted, can both generate and execute a plan of how to verify itself in order to check its own work, and finally incorporate this analysis into an improved response.
The process entails four core steps:
1. Generate Baseline Response: Given a query, generate the response using the LLM.
2. Plan Verifications: Given both query and baseline response, generate a list of verification questions that could help to self-analyze if there are any mistakes in the original response.
3. Execute Verifications: Answer each verification question in turn, and hence check the answer against the original response to check for inconsistencies or mistakes.
4. Generate Final Verified Response: Given the discovered inconsistencies (if any), generate a revised response incorporating the verification results.
Conditioned on the original query and the baseline response, the model is prompted to generate a series of verification questions that test the factual claims in the original baseline response. For example, if response may contains the statement “The Mexican–American War was an armed conflict between the United States and Mexico from 1846 to 1848”, then one possible verification question to check those dates could be “When did the Mexican American war start and end?” It is important to highlight that verification questions are not templated and the language model is free to phrase these in any form it wants and they also do not have to closely match the phrasing of the original text.
Given the planned verification questions, the next step is to answer them in order to assess if any hallucinations exist: the model is used to check its own work. In their paper, the Meta AI researchers investigated several variants of verification execution: Joint, 2-Step, Factored and Factor+Revise.
Joint: In the Joint method, the afore-mentioned planning and execution steps (2 and 3) are accomplished by using a single LLM prompt, whereby the few-shot demonstrations include both verification questions and their answers immediately after the questions.
2-Step: in this method, there is a first step in which verification prompts are generated and then these verification questions are answered in a second step, where crucially the context given to the LLM prompt only contains the questions, and not the original baseline response and hence cannot repeat those answers directly.
Factored: this method consists of answering all questions independently as separate prompts. those prompts do not contain the original baseline response and are hence not prone to simply copying or repeating it.
Factor+Revise: in this method, after answering the verification questions, the overall CoVe pipeline then has to either implicitly or explicitly cross-check whether those answers indicate an inconsistency with the original responses. For example, if the original baseline response contained the phrase “It followed in the wake of the 1845 U.S. annexation of Texas. . . ” and CoVe generated a verification question such as “When did Texas secede from Mexico?”, which would be answered with 1836 then an inconsistency should be detected by this step.
And in the final part of this four-step process, the improved response that takes verification into account is generated. This is executed through taking into account all of the previous reasoning steps -the baseline response and verification question answer pairs-, so that the corrections can happen.
As a conclusion, Chain-of-Verification (CoVe) is an approach to reduce hallucinations in a large language model by deliberating on its own responses and self-correcting them. LLMs are able to answer verification questions with higher accuracy than when answering the original query, by breaking down the verification into a set of simpler questions. And besides, when answering the set of verification questions, controlling the attention of the model so that it cannot attend to its previous answers (factored CoVe) helps alleviate copying the same hallucinations.
Stated the above, CoVe does not remove hallucinations completely from the generated outcomes. While this approach gives clear improvements, the upper bound to the improvement is limited by the overall capabilities of the model, e.g. in identifying and knowing what it knows. In this regard, the use of external tools by language models -for instance,RAG,-to gain further information beyond what is stored in its weights- would grant very likely promising results.
In 2020 Meta (then known as Facebook) published the paper Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, which came up with a framework called retrieval-augmented generation (RAG) to give LLMs access to information beyond their training data.
Large language models can be inconsistent. Sometimes they can grant a perfect answer to a question, but other times they regurgitate aleatory facts from their training data.
Retrieval-augmented generation (RAG) is a technique for enhancing the accuracy and reliability of generative AI models with facts fetched from external sources. In other words, it fills a gap in how LLMs work. Under the hood, LLMs are neural networks, typically measured by how many parameters they contain. An LLM’s parameters essentially represent the general patterns of how humans use words to form sentences. That deep understanding makes LLMs useful in responding to general prompts extremely fast. Nonetheless, it does not serve users who want a deeper dive into a current or more specific topic. Retrieval-augmented generation (RAG) gives models sources they can cite, so users can check any claims. That builds trust. What’s more, the technique can help models clear up ambiguity in a user query.
The roots of the technique go back at least to the early 1970s. That’s when researchers in information retrieval (IR) prototyped what they called question-answering systems, apps that use natural language processing to access text initially in narrow topics.
Implementing RAG in an LLM-based question answering system has two main benefits: It ensures that the model has access to the most current, reliable facts, and that users have access to the model’s sources, ensuring that the accuracy of responses can be easily checked.
By grounding an LLM on a set of external, verifiable facts, the model has fewer opportunities to “hallucinate” or mislead information. RAG allows LLMs to build on a specialized body of knowledge to answer questions in more accurate way. It also reduces the need for users to continuously train the model on new data and update its parameters, as circumstances evolve. In this way, RAG can lower the computational and financial costs of running LLM-powered chatbots in an enterprise setting.
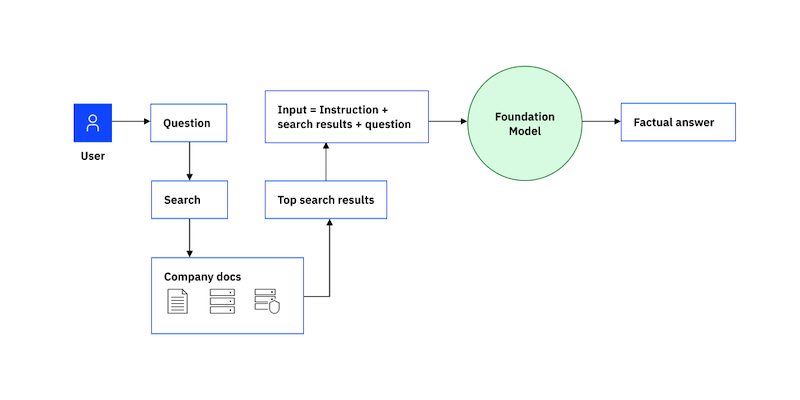
RAG has two phases: retrieval and content generation. In the retrieval phase, algorithms search for and retrieve snippets of information relevant to the user’s prompt or question. In an open-domain, consumer setting, those facts can come from indexed documents on the internet; in a closed-domain, enterprise setting, a narrower set of sources are typically used for added security and reliability.
This collection of outside information is sent to the language model along with the user’s request. During the generative phase, the LLM creates an appealing answer that is customized for the user currently using the enhanced prompt and its internal representation of its training data. A chatbot can then be given the response together with connections to its original sources. The entire procedure can be represented graphically as follows:
Summing up, customer queries are not always straightforward. They can be ambiguously worded, complex, or require knowledge the model either doesn’t have or can’t easily parse. These are the conditions in which LLMs are prone to making things up. LLMs need to be explicitly trained to recognize questions they can’t answer, it may need though to see thousands of examples of questions that can and can’t be answered. Only then can the model learn to identify an unanswerable question, and probe for more detail until it hits on a question that it has the information to answer. RAG is currently the best-known tool for grounding LLMs on the latest, verifiable information, and it allows LLMs to go one step further by greatly reducing the need to feed and retrain the model on fresh examples.
For much time it seemed that in the computing landscape the main application of graphs were only related to ontology engineering, so when my colleague Mihael shared with me the paper “Graph of Thoughts: Solving Elaborate Problems with Large Language Models” -published by the end of August-, I thought we might be in the right path to re-discover the power to representing knowledge of these structures. In the afore-mentioned paper, the authors harness the graph abstraction as a key mechanism that enhances prompting capabilities in LLMs.
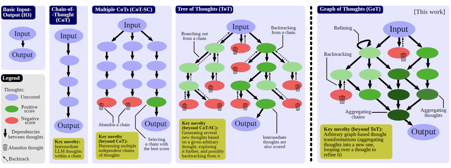
Prompt engineering is one of the central new domains of the large language model research. However, designing effective prompts is a challenging task. Graph of Thoughts (GoT) is a new paradigm that enables the LLM to solve different tasks effectively without any model updates.The key idea is to model the LLM reasoning as a graph, where thoughts are vertices and dependencies between thoughts are edges.
Human’s task solving is often non-linear, and it involves combining intermediate solutions into final ones, or changing the flow of reasoning upon discovering new in sights. For example, a person could explore a certain chain of reasoning, backtrack and start a new one, then realize that a certain idea from the previous chain could be combined with the currently explored one, and merge them both into a new solution, taking advantage of their strengths and eliminating their weaknesses. GoT reflects this, so to say, anarchic reason process with its graph structure.
Nonetheless, let’s take a step back: besides Graph of Thoughts, there are other approaches for prompting:
Input-Output (IO): a straightforward approach in which we use an LLM to turn an input sequence x into the output y directly, without any intermediate thoughts.
Chain-of-Thought (CoT): one introduces intermediate thoughts a1, a2,… between x and y. This strategy was shown to significantly enhance various LLM tasks over the plain IO baseline, such as mathematical puzzles or general mathematical reasoning.
Multiple CoTs: generating several (independent) k CoTs, and returning the one with the best output, according to certain metrics.
Tree of Thoughts (ToT): it enhances Multiple CoTs by modeling the process of reasoning as a tree of thoughts. A single tree node represents a partial solution. Based on a given node, the thought generator constructs a given number k of new nodes. Then, the state evaluator generates scores for each such new node.
Explained in a more visual way:
Image taken from the paper “Graph of Thoughts: Solving Elaborate Problems with Large Language Models”
The design and implementation of GoT, according to the authors, consists of four main components: the Prompter, the Parser, the Graph Reasoning Schedule (GRS), and the Thought Transformer:
The Prompter prepares the prompt to be sent to the LLM, using a use-case specific graph encoding.
The Parser extracts information from the LLM’s thoughts, and updates the graph structure accordingly.
The GRS specifies the graph decomposition of a given task, i.e., it prescribes the transformations to be applied to LLM thoughts, together with their order and dependencies.
The Thought Transformer applies the transformations to the graph, such as aggregation, generation, refinement, or backtracking.
Finally, the authors evaluate GoT on four use cases -sorting, keyword counting, set operations, and document merging-, and compare it to other prompting schemes in terms of quality, cost, latency, and volume. The authors show that GoT outperforms other schemes, especially for tasks that can be naturally decomposed into smaller subtasks, are solved individually, and then merged for a final solution.
Summing up, another breath of fresh air in this hecticly evolving world of AI; this time combining abstract reasoning, linguistics, and computer sciences. Pas mal at all.