As mentioned in our post “China: Techno-socialism Seasoned with Artificial Intelligence“, in its aim of gaining a global leadership role, China launched the Belt and Road Initiative in 2013: a global infrastructure development strategy to invest in more than 150 countries and international organizations. The BRI was composed of six urban development land corridors linked by road, rail, energy, and digital infrastructure and the Maritime Silk Road, linked by the development of ports.
In 2015, the Chinese government published the “Vision and Actions on Jointly Building Silk Road Economic Belt and 21st Century Maritime Silk Road”, introducing the concept of “Information Silk Road” as a component of BRI -later to be rebranded as “digital’ to encompass its broader aspirations. In 2017, during the BRI Forum in Beijing, Xi Jinping stated the use of AI and big data would be incorporated in the future of BRI as well, further illustrating its broad and ever-evolving nature. The DSR is an important component of China’s Belt and Road Initiative (BRI); it covers a wide array of areas, ranging from telecommunications networks, to ‘Smart City’ projects, to e-commerce, to Chinese satellite navigation systems, and of course AI.
The DSR aims at the global expansion of Chinese technologies to markets in which western players have previously dominated, or in developing countries that are only now undergoing a technological revolution. The implementation of China’s DSR has mainly covered the developing countries of Africa, Asia, Latin America, the Middle East, and Eastern Europe. China presents the DSR as a tool for development, innovation, and technological evolution. However, in its ambitions and impact, the DSR is also a question of geopolitics, as it facilitates China’s attempt to establish itself as a major global power across a growing number of technical and research fields, and regions.
With the growing prominence of the DSR, some Western countries have voiced their concerns about the potential risks related to Chinese technology and involvement in sensitive sectors. Both the US and EU have taken steps to counter the rising influence of the DSR. As a tool to contest the Chinese initiative, the US launched the ‘Clean Network’ initiative. Said that, the EU does not have a unified stance on cooperation with China on the DSR. Among 27 members, there are ‘champions’ of the pushback against China, especially among Central and Eastern European countries like Czechia, Slovakia, Slovenia, and Romania, that have aligned with the US’ initiative. Others, like France, have not introduced outright bans but have de facto decided to exclude “untrusted vendors”, and to focus on the European companies and equipment due to security concerns. Germany, on the contrary, is still considering the inclusion of the Chinese companies in the construction of its 5G infrastructure, for instance.
Western Balkans is a region that has been often seen as a springboard by China regarding its presence in Europe. Chinese efforts to include Serbia in the DSR have been more than welcomed and hence Serbia has become a main stop for the Chinese initiative in the region.
Serbia has developed extensive and strategic relations with China over the past decade. The partnership has also included cooperation within the framework of the DSR. Serbia and China signed the Strategic Agreement on Economic, Technological, and Infrastructural cooperation in 2009. That agreement was a starting point for the development of the contemporary relations between two countries and a cornerstone for future joint projects. During the visit of Chinese leader Xi Jinping to Belgrade in 2016, the two countries established a Comprehensive Strategic Partnership.
DSR has reached Serbia and made it the focal point in the Western Balkans. However, cooperation could come with a price. If Serbia relies too much on China in its technological development and does not differentiate partner companies and suppliers, it may become too dependent on its Chinese partners. The absence of diversification can jeopardize the sustainability of the system and the possibility of further improvements of the system in the future. The need of not being dependent on foreign technology is a lesson perfectly learned and practiced by the Chinese authorities concerning AI.
Chinese Non-dependency Policy Regarding GenAI / LLMs
For China and Chinese companies, developing indigenous LLMs is a matter of independence from foreign technologies and also a matter of national pride. Since August 2023, when China’s rules on generative AI came into effect, 46 different LLMs developed by 44 different companies were approved by the authorities. The legislation requires companies to ensure that the models’ responses align with the communist values and also undergo a security self-assessment, which has, however, not been defined until recently. Besides the afore-mentioned approved models, it is estimated that there are more than 200 different LLMs currently functioning in China.
The first wave of models approved in August 2023 was predominantly general LLM models developed by the biggest players in China’s technological market – Baidu, Tencent, Alibaba, Huawei, iFlytek, SenseTime, and ByteDance. Besides these companies, Chinese research institutions, namely the Chinese Academy of Sciences and Shanghai Artificial Intelligence Laboratory, received approvals for their models. In the following batches, models with specific applications started to appear: models designed for recruitment purposes -ranging from CV formatting to providing recommendations; models designed to help companies with cyber security assessments and risk prevention; models designed for readers to interact with their favorite literary characters; models aimed at video content generation based on an article or an idea description; and models providing recommendations to customers and serve as AI assistants.
In March 2024, China’s National Information Security Standardization Technical Committee (TC260) published its basic security requirements for generative AI, which qualifies as a technical document providing detailed guidance for authorities and providers of AI services. This text sets measures regarding the security of training data. Providers must randomly choose 4,000 data points from each training corpus and the number of ‘illegal’ or ‘harmful’ information should not exceed five percent. Otherwise, the corpus may not be used for training. Developers are also required to maintain information about the sources of the training data and the collection processes, and acquire agreement or other authorization to use data for training when using open-source data. This document also provides detailed guidance regarding the evaluation of the model’s responses. Providers are required to create a 2,000-question bank designed to control the model’s outputs in the case of areas defined as “security risks.” -everything which might mean a violation or threat to the communist values.
Importantly and as final note concerning the willingness of being independent from foreign technical developments, the newest AI rules stipulate that Chinese companies are not allowed to use unregistered third-party foundation models to provide public services. This means that access to LLMs developed outside China becomes even more limited and some of the Chinese AI companies who have built their applications based on ChatGPT or LlaMa, for instance, will need to find other solutions.
More than ever the geopolitical battlefield is played mainly on the technological / AI realm.
Artificial intelligence has become a genuine instrument of power. This is as true for hard power (military applications) as for soft power (economic impact, political and cultural influence, etc.). Whilst the United States and China dominate the market and impose their pace: Europe, lagging behind, is trying to respond by issuing new regulations; Africa has become a battlefield for the new digital empires, and Ukraine has turned into the test-bed for AI-based military innovations and developments.
In September 2017 Vladimir Putin, speaking before a group of Russian students and journalists, stated: “Artificial intelligence is the future. . . Whoever becomes the leader in this sphere will become the ruler of the world.” Sharp and accurate. AI is a more generic term than it seems: in fact, artificial intelligence is a collective imaginary onto which we project our hopes and our fears. The rapid progress of AI makes it a powerful tool from the economic, political, and military standpoints. AI will help determine the international order for decades to come, stressing and accelerating the dynamics of an old cycle in which technology and power reinforce one another.
Nowadays we are witnessing to the birth of digital empires. These are the result of an association between multinationals, supported or controlled to varying degrees by the states that financed the development of the techno-scientific bases on which these companies could innovate and thrive. These digital empires would benefit from economies of scale and the acceleration of their concentration of power in the economic, military, and political fields thanks to AI. They would become the major poles governing the totality of international affairs, returning to a “logic of blocs.”
It would be tempting to think that AI is a neutral tool but not at all, indeed. Artificial intelligence is not situated in a vacuum devoid of human interests. Big data, computing power, and machine learning -the three foundations behind the rise of AI- in fact form a complex socio-technical system in which human beings have played and will continue to play a central part. Thus, it is not really a matter of “artificial” intelligence but rather of “collective” intelligence, involving increasingly massive, interdependent, and open communities of actors with power dynamics of their own. Let’s explain this framework:
Teams of engineers construct vast sets of data (produced by each and all: consumers, salesmen, workers, users, citizens, Governments, etc.), design, test, and parameter algorithms, interpret the results, and determine how they are implemented in our societies. Equipped with telephones and ever more interconnected “intelligent” objects, billions of people use AI every day, thus participating in the training and development of its cognitive capacities.
For the majority of these companies, the product is free or inexpensive (for example, the use of a search engine or a social network). As in the media economy, the essential thing for these platforms is to invent solutions that mobilize the “available human brain time” of the users, by optimizing their experience, in order to transform attention into engagement, and engagement into direct or indirect incomes. In addition to concentrating on the attention of the users, the big platforms use their data as raw material. These data are analyzed to profile and better understand users in order to present them with personalized products, services, and experiences at the right time.
Even if their products and services have unquestionably benefited users worldwide, these companies (Apple, Alibaba, Amazon, Huawei, Microsot, Xiaomi, Baidu, Tencent, Facebook, Google…) are also engaged in a zero-sum contest to capture our attention, which they need to monetize their products. Constantly forced to surpass their competitors, the various platforms depend on the latest advances in the neurosciences to deploy increasingly persuasive and addictive techniques, all in order to keep users glued to their screens. By doing this, they influence our perception of reality, our choices and behaviors, in a powerful and as yet completely unregulated form of soft power. The development of AI and its worldwide use are thus constitutive of a type of power making it possible, by non-coercive means, to influence actors’ behavior or even their definition of their own interests. In this sense, one can thus speak of a “political project” on the part of the digital empires, commingled with the mere quest for profit.
The development of AI corresponds to the dynamics of economies of scale and scope, as well as to the effects of direct and indirect networks: the digital mega-platforms are in a position to collect and structure more data on consumers, and to attract and finance the rare talents capable of mastering the most advanced functions of AI. As Cédric Villani wrote in Le Monde in June 2018: “These big platforms capture all the added value: the value of the brains they recruit, and that of the applications and services, by the data that they absorb. The word is very brutal, but technically it is a colonial kind of procedure: you exploit a local resource by setting up a system that attracts the value added to your economy. That is what is called cyber-colonization“.
National actors are increasingly aware of the strategic, economic, and military stakes of the development of AI. In the past 24 months, France, Canada, China, Denmark, the European Commission, Finland, India, Italy, Japan, Mexico, the Scandinavian and Baltic region, Singapore, South Korea, Sweden, Taiwan, the United Arab Emirates, and the United Kingdom have all unveiled strategies for promoting the use and development of AI. Not all countries can aspire to leadership in this sphere. Rather, it is a matter of identifying and constructing comparative advantages, and of meeting the nation’s specific needs. Some states concentrate on scientific research, others on the cultivation of talent and education, still others on the adoption of AI in administration, or on ethics and inclusion. India, for instance, wants to become an “AI garage” by specializing in applications specific to developing countries. Poland is exploring aspects related to cybersecurity and military uses.
Today, the United States and China form an AI duopoly based on the critical dimensions of their markets and their laissez-faire policies regarding personal data protection. The same as USA, China has also integrated AI into its geopolitical strategy. Since 2016, its “Belt & Road” initiative for the construction of infrastructures connecting Asia, Africa, and Europe has included a digital component under the “Digital Belt and Road” program. The program’s latest advance was the creation of a new international center of excellence for “Digital Silk Roads” in Thailand in February 2018.
And Europe? Just falling far behind China and the United States in techno-industrial terms. The European approach seems to consist in taking advantage of its market of 500 million consumers to provide the foundations of an ethical industrial model of AI, while renegotiating a de facto strategic partnership with the United States.
Private investment is the key element and Europe lags really behind. The US is leading the race (€44 billion) in 2022, followed by China (€12 billion), and the EU and the United Kingdom (UK) together attracting €10.2 billion worth of private investment, according to 2023 AI Index of Stanford University. The AI revolution is perceived in Europe as a wave coming from abroad that threatens its socio-economic model, to be protected against. The EU is searching for model of AI that ties together the reclamation of sovereignty and the quest for power with respect for human dignity. Balancing these three desiderata will not be easy: by regulating from a position of extreme weakness and industrial dependency in relation to the Americans or the Chinese, Europe is likely to block its own rise to power.
Africa – The great and not anymore forgotten battlefield
The African continent is practically virginal in terms of digital infrastructures oriented towards AI. The Kenyan government is to date the only one to develop a strategy in this respect. However, Africa has enormous potential for exploring the applications of AI and inventing new business and service models. Chinese investments in Africa have intensified over the last decade, and China is currently the primary trade partner of the African nations, followed by India, France, the United States, and Germany. Africa is probably the continent where cyber-imperialisms are most evident. Examples of the Chinese industrial presence are numerous there: Transsion Holdings became the first smartphone company in Africa in 2017. ZTE, the Chinese telecommunications giant, provides infrastructure to the Ethiopian government. CloudWalk Technology, a start-up based in Guangzhou, signed an agreement with the Zimbabwean government and will work in particular on facial recognition.
A powerful cyber-colonialist phenomenon is at work here. Africa, confronted with the combined urgencies of development, demography, and the explosion of social inequalities, is embarking on a logical but very unequal techno-industrial partnership with China. As the Americans did to Europe after the war, China massively exports its solutions, its technologies, its standards, and the model of company that goes with these to Africa, while also providing massive financing. Nonetheless, the American AI giants are mounting a counterattack. Google, for example, opened its first AI research center on the continent in Accra. Moreover, GAFAM is multiplying startup incubators and support programs for the development of African talent.
Ukraine – The Test-bed of AI-based military developments
Early on the morning of June 1, 2022, Alex Karp, the CEO of Palantir Technologies, crossed the border between Poland and Ukraine on foot with five colleagues. A pair of Toyota Land Cruisers awaited on the other side to take them to Kyiv to meet the Ukrainian President Volodymyr Zelensky. Karp told Zelensky he was ready to open an office in Kyiv and deploy Palantir’s data and artificial-intelligence software to support Ukraine’s defense.
The progress of this alliance has been striking. In the year and a half since Karp’s initial meeting with Zelensky, Palantir has embedded itself in the day-to-day work of a wartime foreign government in an unprecedented way. More than half a dozen Ukrainian agencies, including its Ministries of Defense, Economy, and Education, are using the company’s products. Palantir’s software, which uses AI to analyze satellite imagery, open-source data, drone footage, and reports from the ground to present commanders with military options. Ukrainian officials state thez are using the company’s data analytics for projects that go far beyond battlefield intelligence, including collecting evidence of war crimes, clearing land mines, resettling displaced refugees, and rooting out corruption. Palantir was so keen to showcase its capabilities that it provided them to Ukraine free of charge.
It is far from the only tech company assisting the Ukrainian war effort. Giants like Microsoft, Amazon, Google, and Starlink have worked to protect Ukraine from Russian cyberattacks, migrate critical government data to the cloud, and keep the country connected, committing hundreds of millions of dollars to the nation’s defense. The controversial U.S. facial-recognition company Clearview AI has provided its tools to more than 1,500 Ukrainian officials. Smaller American and European companies, many focused on autonomous drones, have set up shop in Kyiv too.
Some of the lessons learned on Ukraine’s battlefields have already gone global. In January 2024 the White House hosted Palantir and a handful of other defense companies to discuss battlefield technologies used against Russia in the war. The battle-tested in Ukraine stamp seems to be working.
Ukraine’s use of tools provided by companies like Palantir and Clearview also raises complicated questions about when and how invasive technology should be used in wartime, as well as how far privacy rights should extend. Human-rights groups and privacy advocates warn that unchecked access to this tool, which has been accused of violating privacy laws in Europe, could lead to mass surveillance or other abuses. That may well be the price of experimentation. Ukraine is a living laboratory in which some of these AI-enabled systems can reach maturity through live experiments and constant, quick reiteration. Yet much of the new power will reside in the hands of private companies, not governments accountable to their people.
Summing up, AI is indeed an instrument of power right now, and it will be increasingly so as its applications develop, particularly in the military field. However, focusing exclusively on hard power would be a mistake, insofar as AI exercises indirect cultural, commercial, and political influence over its users around the world. This soft power, which especially benefits the American and Chinese digital empires, poses major problems of ethics and governance. The big platforms must integrate these ethical and political concerns into their strategy. AI, like any technological revolution, offers great opportunities, but also presents —overlapping with these— many risks.
Upon coping with LLM generative linguistic capabilities and prompt engineering, one of the main challenges to be tackled is the risk of hallucinations. In the fouth quarter 2023 a new approach to fight and reduce them in LLM outcomes was tested and published by a group of researchers from Meta AI: Chain-of-Verification (CoVe).
What these researchers aimed at was to prove the ability of language models to deliberate on the responses they give in order to correct their mistakes. In the Chain-of-Verification (CoVe) method the model first drafts an initial response; then plans verification questions to fact-check its draft; subsequently answers those questions independently so that the answers are not biased by other responses; and eventually generates its verified improved response.
Setting up the stage
Large Language Models (LLMs) are trained on huge corpora of text documents with billions of tokens of text. It has been shown that as the number of model parameters is increased, performance improve in accuracy, and larger models can generate more correct factual statements.
However, even the largest models can still fail, particularly on lesser known long-tailed distribution facts; i.e. those that occur relatively rarely in the training corpora. In those cases where the model is incorrect, they instead generate an alternative response which is typically plausible looking, but an incorrect one: a hallucination.
The current wave of language modeling research goes beyond next word prediction, and has focused on their ability to reason. Improved performance in reasoning tasks can be gained by encouraging language models to first generate internal thoughts or reasoning chains before responding, as well as updating their initial response through self-critique. This is the line of research followed by the Chain-of-Verification (CoVe) method: given an initial draft response, firstly it plans verification questions to check its work, and then systematically answers those questions in order to finally produce an improved revised response.
The Chain-of-Verification Approach
This approach assumes access to a base LLM that is capable of being prompted with general instructions in either a few-shot or zero-shot fashion. A key assumption in this method is that this language model, when suitably prompted, can both generate and execute a plan of how to verify itself in order to check its own work, and finally incorporate this analysis into an improved response.
The process entails four core steps:
1. Generate Baseline Response: Given a query, generate the response using the LLM.
2. Plan Verifications: Given both query and baseline response, generate a list of verification questions that could help to self-analyze if there are any mistakes in the original response.
3. Execute Verifications: Answer each verification question in turn, and hence check the answer against the original response to check for inconsistencies or mistakes.
4. Generate Final Verified Response: Given the discovered inconsistencies (if any), generate a revised response incorporating the verification results.
Conditioned on the original query and the baseline response, the model is prompted to generate a series of verification questions that test the factual claims in the original baseline response. For example, if response may contains the statement “The Mexican–American War was an armed conflict between the United States and Mexico from 1846 to 1848”, then one possible verification question to check those dates could be “When did the Mexican American war start and end?” It is important to highlight that verification questions are not templated and the language model is free to phrase these in any form it wants and they also do not have to closely match the phrasing of the original text.
Given the planned verification questions, the next step is to answer them in order to assess if any hallucinations exist: the model is used to check its own work. In their paper, the Meta AI researchers investigated several variants of verification execution: Joint, 2-Step, Factored and Factor+Revise.
Joint: In the Joint method, the afore-mentioned planning and execution steps (2 and 3) are accomplished by using a single LLM prompt, whereby the few-shot demonstrations include both verification questions and their answers immediately after the questions.
2-Step: in this method, there is a first step in which verification prompts are generated and then these verification questions are answered in a second step, where crucially the context given to the LLM prompt only contains the questions, and not the original baseline response and hence cannot repeat those answers directly.
Factored: this method consists of answering all questions independently as separate prompts. those prompts do not contain the original baseline response and are hence not prone to simply copying or repeating it.
Factor+Revise: in this method, after answering the verification questions, the overall CoVe pipeline then has to either implicitly or explicitly cross-check whether those answers indicate an inconsistency with the original responses. For example, if the original baseline response contained the phrase “It followed in the wake of the 1845 U.S. annexation of Texas. . . ” and CoVe generated a verification question such as “When did Texas secede from Mexico?”, which would be answered with 1836 then an inconsistency should be detected by this step.
And in the final part of this four-step process, the improved response that takes verification into account is generated. This is executed through taking into account all of the previous reasoning steps -the baseline response and verification question answer pairs-, so that the corrections can happen.
As a conclusion, Chain-of-Verification (CoVe) is an approach to reduce hallucinations in a large language model by deliberating on its own responses and self-correcting them. LLMs are able to answer verification questions with higher accuracy than when answering the original query, by breaking down the verification into a set of simpler questions. And besides, when answering the set of verification questions, controlling the attention of the model so that it cannot attend to its previous answers (factored CoVe) helps alleviate copying the same hallucinations.
Stated the above, CoVe does not remove hallucinations completely from the generated outcomes. While this approach gives clear improvements, the upper bound to the improvement is limited by the overall capabilities of the model, e.g. in identifying and knowing what it knows. In this regard, the use of external tools by language models -for instance,RAG,-to gain further information beyond what is stored in its weights- would grant very likely promising results.
Eventually and some months after its presentation at the Geneva Centre for Security Policy, I have had the chance of diving into the book “The AI Wave in Defense Innovation. Assessing Military Artificial Intelligence Strategies, Capabilities, and Trajectories.” Edited by Michael Raska and Richard A. Bitzinger and with the contribution from experts in different fields -AI, intelligence, technology governance, defense innovation…-, this volume is an international and interdisciplinary perspective on the adoption and governance of AI in defense and military innovation by major and middle powers.
From the different chapters, I deem it should be stressed the one titled “AI Ethics and Governance in Defense Innovation. Implementing AI Ethics Framework” by Cansu Canca, owing to the meaningful insights included in it.
For the author, AI use within a military context raises various ethical concerns due to high ethical risks often inherent in these technologies. A comprehensive account of the ethical landscape of AI in the military must also account for the potential ethical benefits. AI ethics within a military context is hence a double-edged sword. To illustrate this dual aspect, Canca lists some ethical pairs of pros and cons:
Precision vs. Aggression
A major area of AI applications for the military is about increasing precision -the Pentagon-funded Project Maven is probable the best example of this.
The military benefits of increased precision in surveillance and potentially in targeting are clear. AI may help search and rescue mission, predict and prevent deadly attacks from the opponent, and eliminate or decrease errors in defense. However, these increased capabilities might also boost the confidence of armed forces and make them more aggressive in their offensive and defensive attacks, resulting in more armed conflicts and more casualties.
Efficiency vs. Lowered Barriers to Conflict
AI systems that reduce the need for human resources, keep humans safe, and allow human officers to use their expertise are beneficial for the military and military personnel. The other side of the coin is the concern that increasing efficiency and safety for the military will also lower the barriers to entering a conflict: if war is both safe and low cost, what would stand in the way of starting one?
Those who lack the technology would be deterred from starting a war, whereas those equipped with the technology could become even more eager to escalate a conflict.
Protecting combatants vs. Neglecting Responsibility and Humanity
Sparing military personnel’s lives and keeping them safe from death and physical and mental harm would be a clear benefit for the military. However, it is never that simple: Can an officer remotely operating a weapon feel the weight of responsibility of “pulling the trigger” as strongly when they are distant from the “other”? Can they view the “other” as possessing humanity, when they are no longer face-to-face with them?
The ethical decision-making of a human is inevitably intertwined with human psychology. How combatants feel about the situation and the other parties necessarily feature in their ethical reasoning. The question is: where, if anywhere, should we draw the line on the spectrum of automation and remote control to ensure that human officers still engage in ethical decision-making, acknowledging the weight of their decisions and responsibility as they operate and collaborate with AI tools?
Military use of AI is not good or bad; it is a mixed bag. For that reason, more than ever it is needed the creation and implementation of frameworks for the ethical design, development, and deployment of AI systems.
AI Ethics Framework
AI ethics has increasingly been a core area of concern across sectors, particularly since 2017, when technology-related scandals slowly started to catch the public’s attention. AI ethics is concerned with the whole AI development and deployment cycle. This includes research, development, design, deployment, use, and even the updating stages of the AI life cycle.
Each stage presents its unique ethical questions, being some of them:
Does the dataset represente the world and, if not, who is left out?
Does the algorithm prioritize a value explicitly or implicitly? And if it does, is this justified?
Does the dashboard provide information for a user to understand the core variables of an AI decision-aid tool?
Did research subjects consent to have their data used?
Do professional such as military officers, managers, physicians, and administrators understand the limitation of the AI tools they are handed?
As users engage with AI tools in their professional or personal daily lives, do they agree to have their data collected and used, and do they understand its risks?
What makes ethical issues AI-specific are the extremely short gap between R&D and practice, the wide-scale and systematic use of AI systems, the increased capabilities of AI systems, and the façade of computational objectivity. Concerning the latter, this point is extremely dangerous because it allows users -such as judges and officers- to put aside their critical approach and prevents them from questioning the system’s results. Inadvertently the AI system leads them to make ethical errors and do so systematically due to their over-reliance on the AI tool.
The ethical questions and issues that AI raises cannot be addressed through this traditional ethics compliance and oversight model. Neither can they be solved solely through regulation. Instead, and according to the author, we need a comprehensive AI ethics framework to address all aspects of AI innovation and use in organizations. A proper AI ethics strategy consists of the playbook component, which includes all ethical guiding materials such as ethics principles, use cases, and tools; the process component, which includes ethics analysis and ethics-by-design components, and structures how and when to integrate these and other ethics components into the organizational operations; and the people component, which structures a network of different ethics roles within the organization.
AI Ethics Playbook
The AI ethics playbook forms the backbone of the AI ethics strategy, consisting of all guidelines and tools to aid ethical decision-making at all levels; i.e., fundamental principles to create a solid basis, accesible and user-friendly tools that help apply these principles, and use cases that demonstrate how to use these tools and bring the principles into action. The AI ethics playbook should be a living document.
As an example, these are the AI ethics principles recommended by the US Department of Defense in 2019:
Responsibility: DoD personnel will exercise appropriate levels of judgement and care concerning the development, deployment, and use of AI capabilities.
Equitability: The DoD will take the required steps to minimize unintended bias in AI capabilities.
Traceability: DoD relevant personnel must possess an appropriate understanding of the technology, development processes, and operational methods applicable to AI capabilities.
Reliability: the safety, security, and effectiveness of AI capabilities will be subject to testing and assurance.
Governability: DoD will design AI capabilities to fulfill their intended functions while processing the ability to detect and avoid unintended consequences, and the ability to disengage or deactivate deployed systems that demonstrate unintended behavior.
AI Ethics Process
AI playbook is inconsequential if there is no process to integrate it into the organization’s operations. Therefore an essential part of an AI ethics strategy is figuring out how to add the playbook into the organization’s various operations seamlessly. The objective of the AI ethics process is to create systematic procedures for ethics decisions which include: structuring the workflow to add “ethics checkpoints”; ethics analysis and ethics-by-design sessions; documenting ethics decisions and adding them into the playbook as use cases; and finally ensuring a feedback loop between new decisions and the updating of the playbook when needed.
AI Ethics People
A network of people who carry different roles concerning ethics should be embedded into every layer of the organization. It should be clear from the tasks at hand that the ethics team’s work is distinct from the legal team. Whilst there should be close collaboration between legal and ethics experts, the focus of legal experts and their skills and tools differ significantly from those of ethics experts.
And last but not least, from Canca’s standpoint, an ethics framework without an accountability mechanism would be limited to individuals’ motivation to “do good” rather than functioning as a reliable and strategic organizational tool. To that end, an AI ethics framework should be supported by AI regulations. AI regulations would function as an external enforcing mechanism to define the boundaries of legally acceptable action and to establish a fair playing field for competition. Regulations should also function to support the AI ethics framework by requiring basic components of this framework to be implemented such as an audit mechanism for the safety, reliability, and fairness of AI systems. Having such a regulatory framework for AI ethics governance would also help create citizen trust.
In 2020 Meta (then known as Facebook) published the paper Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, which came up with a framework called retrieval-augmented generation (RAG) to give LLMs access to information beyond their training data.
Large language models can be inconsistent. Sometimes they can grant a perfect answer to a question, but other times they regurgitate aleatory facts from their training data.
Retrieval-augmented generation (RAG) is a technique for enhancing the accuracy and reliability of generative AI models with facts fetched from external sources. In other words, it fills a gap in how LLMs work. Under the hood, LLMs are neural networks, typically measured by how many parameters they contain. An LLM’s parameters essentially represent the general patterns of how humans use words to form sentences. That deep understanding makes LLMs useful in responding to general prompts extremely fast. Nonetheless, it does not serve users who want a deeper dive into a current or more specific topic. Retrieval-augmented generation (RAG) gives models sources they can cite, so users can check any claims. That builds trust. What’s more, the technique can help models clear up ambiguity in a user query.
The roots of the technique go back at least to the early 1970s. That’s when researchers in information retrieval (IR) prototyped what they called question-answering systems, apps that use natural language processing to access text initially in narrow topics.
Implementing RAG in an LLM-based question answering system has two main benefits: It ensures that the model has access to the most current, reliable facts, and that users have access to the model’s sources, ensuring that the accuracy of responses can be easily checked.
By grounding an LLM on a set of external, verifiable facts, the model has fewer opportunities to “hallucinate” or mislead information. RAG allows LLMs to build on a specialized body of knowledge to answer questions in more accurate way. It also reduces the need for users to continuously train the model on new data and update its parameters, as circumstances evolve. In this way, RAG can lower the computational and financial costs of running LLM-powered chatbots in an enterprise setting.
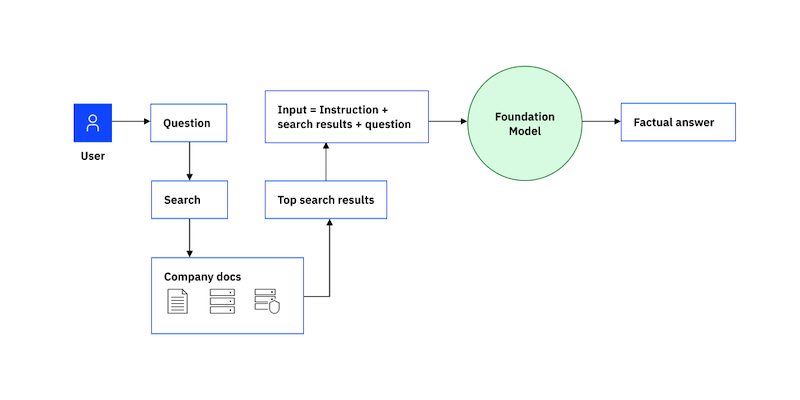
RAG has two phases: retrieval and content generation. In the retrieval phase, algorithms search for and retrieve snippets of information relevant to the user’s prompt or question. In an open-domain, consumer setting, those facts can come from indexed documents on the internet; in a closed-domain, enterprise setting, a narrower set of sources are typically used for added security and reliability.
This collection of outside information is sent to the language model along with the user’s request. During the generative phase, the LLM creates an appealing answer that is customized for the user currently using the enhanced prompt and its internal representation of its training data. A chatbot can then be given the response together with connections to its original sources. The entire procedure can be represented graphically as follows:
Summing up, customer queries are not always straightforward. They can be ambiguously worded, complex, or require knowledge the model either doesn’t have or can’t easily parse. These are the conditions in which LLMs are prone to making things up. LLMs need to be explicitly trained to recognize questions they can’t answer, it may need though to see thousands of examples of questions that can and can’t be answered. Only then can the model learn to identify an unanswerable question, and probe for more detail until it hits on a question that it has the information to answer. RAG is currently the best-known tool for grounding LLMs on the latest, verifiable information, and it allows LLMs to go one step further by greatly reducing the need to feed and retrain the model on fresh examples.