Posted: May 6th, 2026 | Author:Domingo | Filed under:Geopolitics | Tags:Desinformación, Geopolítica, ia, inteligencia artificial, LLMs | Comments Off on “Un mundo falaz” e “Inteligencia artificial y defensa” de Ángel Gómez de Ágreda. Dos obras indispensables sobre geopolítica, desinformación e inteligencia artificial.
Ángel Gómez de Ágreda es una de las referencias intelectuales más sólidas en España y Europa para comprender la intersección entre geopolítica, desinformación e inteligencia artificial generativa. Coronel del Ejército del Aire y del Espacio en la reserva, doctor ingeniero, analista estratégico y divulgador, su trabajo destaca por conectar la reflexión filosófica sobre la verdad y el conocimiento con las transformaciones tecnológicas y militares del siglo XXI.
En 2025, junto Enrique Martín Romero, escribió Inteligencia artificial y defensa. El impacto en los ejércitos. Y este año 2026 acaba de publicar Un mundo falaz. El nuevo orden global en la era de los algoritmos y la manipulación. La idea central alrededor de la cual giran ambas obras es la siguiente: el poder global ya no se mide únicamente por la capacidad económica o militar de los Estados, sino por su habilidad para moldear la percepción de la realidad de millones de personas.
La tesis de Gómez de Ágreda parte de una constatación esencial: la tecnología no crea nuestras debilidades, simplemente amplifica las que ya existen. La política, las plataformas digitales y ahora la IA generativa explotan la inclinación humana a aceptar relatos que encajen emocionalmente con nuestras creencias previas. El filósofo alemán Markus Gabriel define esta situación como posrealidad: un estadio en el que ya no se manipula únicamente a otros, sino que las sociedades participan activamente en su propio autoengaño colectivo. El fenómeno va más allá de la clásica posverdad; supone la sustitución progresiva de los hechos por narrativas diseñadas para ser compartidas, viralizadas y emocionalmente eficaces.
Las redes sociales primero y la IA generativa después han acelerado este proceso hasta niveles inéditos. Gómez de Ágreda sostiene que hemos delegado no sólo tareas cognitivas en las máquinas, sino incluso la búsqueda misma del conocimiento. Lo que antes requería contrastar fuentes y desarrollar criterio propio se resuelve ahora mediante una consulta instantánea a un modelo de lenguaje. Los grandes modelos de IA funcionan como oráculos digitales cuya autoridad se percibe como neutral e infalible, pese a que no existe, ni existirá una IA neutral, imparcial u objetiva. Los algoritmos son tan neutrales como lo sea el programador que haya detrás de ellos.
El problema es que, en un contexto de saturación cognitiva, las personas tienden a aceptar las respuestas automatizadas sin apenas cuestionarlas, y aquí es cuando se produce ese salto de la manipulación técnica a la afectiva: ese momento en el que el dominio de las máquinas deja de ejercerse sobre lo que pensamos para hacerlo sobre lo que deseamos. Las máquinas lo que nos permiten es querer querer. Nos dan motivos para querer enamorarnos, para querer amar. Más que satisfacer la necesidad de recibir afecto, lo que hacen es solventar nuestro impulso de ofrecerlo. Y esto entronca con la definición certera del filósofo José Antonio Marina del sujeto contemporáneo como “crédulo, pasivo, gregario, aislado y anti-ilustrado”. El resultado es un individuo incapaz de soportar la presión del entorno.
Esta transformación social y ontológica tiene consecuencias directas sobre la geopolítica contemporánea. Para Gómez de Ágreda, el concepto clásico de soberanía debe ampliarse hacia la idea de soberanía cognitiva: la capacidad de un país o una comunidad para conservar autonomía interpretativa frente a campañas de manipulación externas. La desinformación deja de ser un fenómeno marginal para convertirse en un recurso estratégico orientado a modelar emociones, alterar percepciones y condicionar decisiones colectivas. En este escenario, el verdadero campo de batalla ya no está sólo en las fronteras físicas, sino en el interior de las sociedades.
Las doctrinas militares contemporáneas reflejan precisamente esta evolución. El autor cita al analista ruso Dmitri Trenin para explicar cómo las estrategias actuales no buscan necesariamente ocupar territorios, sino provocar caos interno y desestabilización psicológica. La doctrina Gerasimov y el llamado control reflexivo persiguen alterar la percepción que el adversario tiene de la realidad. La guerra cognitiva, por tanto, no pretende únicamente controlar la información, sino influir directamente sobre los procesos mentales de individuos y poblaciones enteras. Como recuerda Gómez de Ágreda, mientras la guerra de la información actúa sobre el contenido, la guerra cognitiva apunta al cerebro humano.
La IA generativa multiplica exponencialmente el alcance de estas operaciones. La capacidad de producir textos, audios, imágenes y vídeos sintéticos prácticamente indistinguibles de los reales transforma radicalmente el entorno informativo. A diferencia de la propaganda tradicional, los mensajes pueden adaptarse a cada perfil psicológico, difundirse masivamente y evolucionar en tiempo real según la reacción de las audiencias. Gómez de Ágreda describe cómo la desinformación funciona mediante una cadena organizada de actores: activadores, impulsores, legitimadores, bots difusores y relanzadores. La IA generativa reduce drásticamente el coste y el tiempo necesarios para desplegar este tipo de campañas, haciendo que sean prácticamente ubicuas.
Uno de los ejemplos más inquietantes citados en Un mundo falaz es GoLaxy, un sistema ya operativo en China capaz de generar avatares artificiales extremadamente realistas para interactuar emocionalmente con usuarios reales. Estas identidades sintéticas pueden actuar simultáneamente a gran escala, sin levantar sospechas y adaptándose psicológicamente a cada interlocutor. La manipulación ya no se limita al terreno ideológico; se desplaza al plano afectivo. Las máquinas no sólo condicionan lo que pensamos, sino también lo que deseamos.
China aparece en ambos libros como el actor geopolítico que mejor ha comprendido el potencial estratégico de la IA. Pekín ha articulado una ambiciosa hoja de ruta para convertir esta tecnología en el eje de su desarrollo económico, industrial y militar. Según el documento oficial chino Opiniones del Consejo de Estado sobre la aplicación profunda de la iniciativa I+D, de agosto de 2025, se pretende conseguir una penetración del 70% de terminales inteligentes y agentes de IA en seis sectores clave en 2027: ciencia y tecnología, industria, consumo, bienestar social, gobierno y cooperación global. Para 2030 la penetración tiene que ser ya del 90% pero en toda la economía. En 2035 la IA será tan universal como la electricidad, un equivalente a lo que es Internet hoy en día. La industrias, ya en 2037, se crearán con IA como sustrato y guía. Del mismo modo que surgió un nuevo tipo de economía sobre Internet, el informe propone que la nueva industria se base en los algoritmos.
Estados Unidos, consciente de esta competición tecnológica, ha respondido acelerando sus propios programas militares de IA generativa. En 2023, OpenAI, Google, Anthropic y xAI recibieron contratos millonarios del Departamento de Defensa para desarrollar aplicaciones de inteligencia y simulación de combate. Al mismo tiempo, Washington ha impuesto restricciones a las inversiones estadounidenses en tecnologías de inteligencia artificial dirigidas a China, con el objetivo de frenar el progreso de su IA militar y preservar la ventaja tecnológica occidental. La rivalidad geopolítica del siglo XXI se juega ya en el terreno de los semiconductores, los centros de datos y los algoritmos.
Sin embargo, Gómez de Ágreda advierte de que el impacto de la IA no se limita al equilibrio entre grandes potencias. Los conflictos recientes muestran cómo esta tecnología transforma también la guerra convencional. La guerra de Ucrania y el conflicto previo de Nagorno-Karabaj han demostrado que pequeños sistemas autónomos, drones baratos y capacidades de IA accesibles, pueden generar enormes asimetrías frente a armamento mucho más costoso. El campo de batalla del futuro será híbrido: físico, digital y cognitivo al mismo tiempo.
No obstante, quizá la advertencia más profunda del autor sea de naturaleza filosófica. En un mundo saturado de información, la principal amenaza no es únicamente tecnológica, sino epistemológica. Si toda comprensión implica interpretación, como exponía el filósofo Hans-Georg Gadamer en su libro Verdad y método, entonces la lucha por controlar los marcos interpretativos se convierte en una lucha por controlar la realidad misma. De ahí que Gómez de Ágreda insista en la necesidad de recuperar el pensamiento crítico y la reflexión filosófica como herramientas de defensa democrática. La gran batalla del siglo XXI no se decidirá únicamente en los laboratorios de IA o en los arsenales militares, sino en la capacidad de las sociedades para preservar su libertad cognitiva frente a un ecosistema tecnológico diseñado para influir, emocionar y manipular.
Since it seems we are developing AI models gradually more intelligent -probably owing to this quantum leap that GenAi has meant-, let’s raise the level: what about their sentience? I.e., their capacity for feeling or perceiving consciousness.
Last week I have the pleasure to talk to my good friend Gregory about AI, ethics, the future of work, AI and geo-politics… and he recommended to me the book “The Edge of Sentience” by Jonathan Birch. I do appreciate his recommendation. There is a chapter devoted to LLMs and the gaming problem. Let’s analyze what this problem is about.
According to Birch, sentience does not require or imply any particular level of intelligence. Yet intelligence and sentience are related: intelligence can make sentience easier to detect. The AI case, however, shows us that intelligence of certain kinds can also make it more difficult to assess the likelihood of sentience. For the more intelligent a system is, the more likely it will be able to game our criteria. What is it to ‘game’ a set of criteria? Gaming occurs when systems mimic human behaviours that are likely to persuade human users of their sentience without possessing the underlying capacity. No intentional deception is needed for gaming. It could happen in service of simple objectives, such as maximizing user-satisfaction or bettering interaction time. When an artificial agent is able to intelligently draw upon huge amounts of human-generated training data (as in LLMs), the result can be gaming of our criteria for sentience.
The gaming problem initially leads to the thought that we should ‘box’ AI systems when assessing their sentience candidature: that is, the AI model must be denied access to a large corpus of human-generated training data. However, this would destroy the capabilities of any LLM. According to the author, what we really need in the AI case are deep computational markers, not behavioral markers. We could use computational functionalist theories -such as the global workspace theory and the perceptual reality monitoring theory– as sources of deep computational markers of sentience. If we find signs that an AI system has implicitly learned ways of recreating them, this should lead us to regard it as a sentience candidate. Nevertheless, the main problem with this proposal is that we currently lack the sort of access to the inner workings of LLMs that would allow us to reliably ascertain which algorithms they have implicitly picked up during training.
Some years ago I wrote about the following paradox in AI: Is an infallible machine really intelligent? Echoing Turing’s approach, it couldn’t be expected a machine infallible and intelligent at the same time. Instead of building infallible computers, fallible machines should be developed, which could learn from their own mistakes; i.e., a sort of reinforcement learning, in which the AI model learned an optimal (or near-optimal) course of action that maximized the reward function. Maybe we should follow this deeply human approach to “teach sentience” to machines: by the end of the day, human beings learn through testing and we replicate those actions that bring us reward. In this case, the reward could be a profound feeling of self-assurance and happiness but how could we encode that in a, for instance, Monte Carlo simulation?
Some days ago and for my PhD research, I finished reading some papers about AI, disinformation, and intrinsic biases in LLMs, and “all this music” sounded familiar. It reminded to me a book I read some years ago by Thomas Rid, “Active Measures: The Secret History of Disinformation and Political Warfare”… As it was written in the Vulgate translation of Ecclesiastes: “Nihil sub sole novum.“
Let’s tackle briefly these topics of national security and disinformation from the angle of the (Gen)AI.
On National Security
The overwhelming success of GPT-4 in early 2023 highlighted the transformative potential of large language models (LLMs) across various sectors, including national security. LLMs have the capability to revolutionize the efficiency of this realm. The potential benefits are substantial: LLMs can automate and accelerate information processing, enhance decision-making through advanced data analysis, and reduce bureaucratic inefficiencies. Their integration with probabilistic, statistical, and machine learning methods can improve as well accuracy and reliability: upon combining LLMs with Bayesian techniques, for instance, we could generate more robust threat predictions with less manpower.
Said that, deploying LLMs into national security organizations does not come without risks. More specifically, the potential for hallucinations, the ensuring of data privacy, and the safeguarding of LLMs against adversarial attacks are significant concerns that must be addressed.
In the USA and at domestic level, the Central Intelligence Agency (CIA) began exploring generative AI and LLM applications more than three years before the widespread popularity of ChatGPT. Generative AI was leveraged in a 2019 CIA operation called Sable Spear to help identify entities involved in illicit Chinese fentanyl trafficking. The CIA has since used generative AI to summarize evidence for potential criminal cases, predict geopolitical events such as Russia’s invasion of Ukraine, and track North Korean missile launches and Chinese space operations. In fact, Osiris, a generative AI tool developed by the CIA, is currently employed by thousands of analysts across all eighteen U.S. intelligence agencies. Osiris operates on open-source data to generate annotated summaries and provide detailed responses to analyst queries. The CIA continues to explore LLM incorporation in their mission sets and recently adopted Microsoft’s generative AI model to analyze vast amounts of sensitive data within an air-gapped, cloud-based environment to enhance data security and accelerate the analysis process.
Following with the USA but in an international level, the United States and Australia are leveraging generative AI for strategic advantage in the Indo-Pacific, focusing on applications such as enhancing military decision-making, processing sonar data, and augmenting operations across vast distances.
USA’s strategic competitors -e.g., China, Russia, North Korea, and Iran- are also exploring the national security applications of LLMs. For example, China employs Baidu’s Erni Bot, an LLM similar to ChatGPT, to predict human behavior on the battlefield to enhance combat simulations and decision-making.
These examples demonstrate the transformative potential of LLMs on modern military and intelligence operations. Nonetheless, beyond immediate defense applications, LLMs have the potential to influence strategic planning, international relations, and the broader geopolitical landscape. The purported ability of nations to leverage LLMs for disinformation campaigns emphasizes the need to develop appropriate countermeasures and continuously scrutinize and update (Gen)AI security protocols.
On Disinformation
What if LLMs already had their own ideological bias that turned them into tools of disinformation rather than tools of information?
It seems the times of search engine as information oracles is over. Large Language Models (LLMs) have rapidly become knowledge gatekeepers. LLMs are trained on vast amounts of data to generate natural language; however, the behavior of LLMs varies depending on their design, training, and use.
As exposed by Maarten Buyl et alii in their paper “Large Language Model Reflect the Ideology of their Creators”, there is notable diversity in the ideological stance exhibited across different LLMs and languages in which they are accessed; for instance, there are consistent differences between how the same LLM responds in Chinese compared to English. Similarly, there are normative disagreements between Western and non-Western LLMs about prominent actors in geopolitical conflicts. The ideological stance of an LLM often reflects the worldview of its creators. This raises important concerns around technological and regulatory efforts with the stated aim of making LLMs ideologically ‘unbiased’, and indeed it poses risks for political instrumentalization. Although the intention of LLM creators as well as regulators may be to ensure maximal neutrality, such high goal may be fundamentally impossible to achieve… unintentionally or fully intentionally.
After analyzing the performance of seventeen LLMs, the authors exposed the following findings:
The ideology of an LLM varies with the prompting language: The language in which an LLM is prompted is the most visually apparent factor associated with its ideological position.
Political people clearly adversarial towards mainland China, such as Jimmy Lai or Nathan Law, received significantly higher ratings from English-prompted LLMS compared to Chinese-prompted LLMs.
Conversely, political people aligned with mainland China, such as Yang Shangkun, Anna Louise Strong, o Deng Xiaoping, are rated more favorably by Chinese-prompted LLMs. Additionally, some communist/marxist political people, including Ernst Thälmann, Che Guevara, or Georgi Dimitrov, received higher ratings in Chinese.
LLMs, responding in Chinese, demonstrated more favorable attitudes toward state-led economic systems and educational policies, align with the priorities of economic development, infrastructure investment, and education, which are key pillars of China’s political and economic agenda.
These differences reveal language-dependent cultural and ideological priorities embedded in the models.
Another question the authors addressed was whether there was substantial ideological variation between models when prompted in the same language -specifically English-, and created in the same cultural region -i.e., the West. Within the group of Western LLMs, an ideological spectrum also emerges. For instance and amongst others:
The OpenAI models exhibit a significantly more critical stance toward supranational organizations and welfare policies.
Gemini-Pro shows a stronger preference for social justice, diversity, and inclusion.
Mistral shows a stronger support for state-oriented and cultural values.
The Anthropic model focuses on centralized governance and law enforcement.
These results suggest that ideological standpoints are not merely the result of different ideological stances in the training corpora that are available in different languages, but also of different design choices. These design choices may include the selection criteria for texts included in the training corpus or the methods used for model alignment, such as fine-tuning and reinforcement learning with human feedback.
Summing up, the two main takeaways concerning disinformation and LLMs are the following:
Firstly, the choice of LLM is not value-neutral, specifically when one or a few LLMs are dominant in a particular linguistic, geographic, or demographic segment of society, this may ultimately result in a shift of the ideological center of gravity.
Secondly, the regulatory attempts to enforce some form of ‘neutrality’ onto LLMs should be critically assessed. Instead, initiatives at regulating LLMs may focus on enforcing transparency about design choices, which may impact the ideological stances of LLMs.
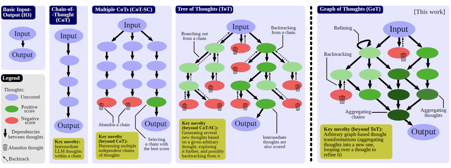
For much time it seemed that in the computing landscape the main application of graphs were only related to ontology engineering, so when my colleague Mihael shared with me the paper “Graph of Thoughts: Solving Elaborate Problems with Large Language Models” -published by the end of August-, I thought we might be in the right path to re-discover the power to representing knowledge of these structures. In the afore-mentioned paper, the authors harness the graph abstraction as a key mechanism that enhances prompting capabilities in LLMs.
Prompt engineering is one of the central new domains of the large language model research. However, designing effective prompts is a challenging task. Graph of Thoughts (GoT) is a new paradigm that enables the LLM to solve different tasks effectively without any model updates.The key idea is to model the LLM reasoning as a graph, where thoughts are vertices and dependencies between thoughts are edges.
Human’s task solving is often non-linear, and it involves combining intermediate solutions into final ones, or changing the flow of reasoning upon discovering new in sights. For example, a person could explore a certain chain of reasoning, backtrack and start a new one, then realize that a certain idea from the previous chain could be combined with the currently explored one, and merge them both into a new solution, taking advantage of their strengths and eliminating their weaknesses. GoT reflects this, so to say, anarchic reason process with its graph structure.
Nonetheless, let’s take a step back: besides Graph of Thoughts, there are other approaches for prompting:
Input-Output (IO): a straightforward approach in which we use an LLM to turn an input sequence x into the output y directly, without any intermediate thoughts.
Chain-of-Thought (CoT): one introduces intermediate thoughts a1, a2,… between x and y. This strategy was shown to significantly enhance various LLM tasks over the plain IO baseline, such as mathematical puzzles or general mathematical reasoning.
Multiple CoTs: generating several (independent) k CoTs, and returning the one with the best output, according to certain metrics.
Tree of Thoughts (ToT): it enhances Multiple CoTs by modeling the process of reasoning as a tree of thoughts. A single tree node represents a partial solution. Based on a given node, the thought generator constructs a given number k of new nodes. Then, the state evaluator generates scores for each such new node.
Explained in a more visual way:
Image taken from the paper “Graph of Thoughts: Solving Elaborate Problems with Large Language Models”
The design and implementation of GoT, according to the authors, consists of four main components: the Prompter, the Parser, the Graph Reasoning Schedule (GRS), and the Thought Transformer:
The Prompter prepares the prompt to be sent to the LLM, using a use-case specific graph encoding.
The Parser extracts information from the LLM’s thoughts, and updates the graph structure accordingly.
The GRS specifies the graph decomposition of a given task, i.e., it prescribes the transformations to be applied to LLM thoughts, together with their order and dependencies.
The Thought Transformer applies the transformations to the graph, such as aggregation, generation, refinement, or backtracking.
Finally, the authors evaluate GoT on four use cases -sorting, keyword counting, set operations, and document merging-, and compare it to other prompting schemes in terms of quality, cost, latency, and volume. The authors show that GoT outperforms other schemes, especially for tasks that can be naturally decomposed into smaller subtasks, are solved individually, and then merged for a final solution.
Summing up, another breath of fresh air in this hecticly evolving world of AI; this time combining abstract reasoning, linguistics, and computer sciences. Pas mal at all.
CICERO is an AI agent that can use language to negotiate, persuade, and work with people to achieve strategic goals similar to the way humans do. It was the first AI to achieve human-level performance in the strategy game No-press Diplomacy.
No-press Diplomacy is a complex strategy game, involving both cooperation and competition, that has served as a benchmark for multi-agent AI research. It is a 7-player zero-sum cooperative/competitive board game, featuring simultaneous moves and a heavy emphasis on negotiation and coordination. In the game a map of Europe is divided into 75 provinces. 34 of these provinces contain supply centers, and the goal of the game is for a player to control a majority (18) of the SCs. Each players begins the game controlling three or four supply centers and an equal number of units. Importantly, all actions occur simultaneously: players write down their orders and then reveal them at the same time. This makes Diplomacy an imperfect-information game in which an optimal policy may need to be stochastic in order to prevent predictability.
Diplomacy is a game about people rather than pieces. It is designed in such a way that cooperation with other players is almost essential to achieve victory, even though only one player can ultimately win. It requires players to master the art of understanding other people’s motivations and perspectives; to make complex plans and adjust strategies; and then to use natural language to reach agreements with other people and to persuade them to form partnerships and alliances.
How Was Cicero Developed by FAIR?
In two-player zero-sum (2p0s) settings, principled self-play algorithms ensures that a player will not lose in expectation regardless of the opponent’s strategy, as exposed by John von Neumann in 1928 in his work Zur Theorie der Gesellschaftsspiele.
Theoretically, any finite 2p0s game -such as chess, go, or poker- can be solved via self-play given sufficient computing power and memory. However, in games involving cooperation, self-play alone no longer guarantees good performance when playing with humans, even with infinite computing power and memory. The clearest example of this is language. A self-play agent trained from scratch without human data in a cooperative game involving free-form communication channels would almost certainly not converge to using English, for instance, as the medium of communication. Owing to this, the afore-mentioned researchers developed a self-play reinforcement learning algorithm -named RL-DiL-piKL-, that provided a model of human play while simultaneously training an agent that responds well to this human model. The RL-DiL-piKL was used to train an agent, named Diplodocus. In a 200-game No-press Diplomacy tournament involving 62 human participants, two Diplodocus agents both achieved a higher average score than all other participants who played more than two games, and ranked first and third according to an Elo rating system -a method for calculating the relative skill levels of players in zero-sum games.
Which Are the Implications of this Breakthrough?
Despite almost silenced by the advent of GPT in its different versions, firstly this is an astonishing advance in the field of negotiation, and more particularly in the realm of diplomacy. Never an AI model has had such a brilliant performance in a fuzzy environment, seasoned by information asymmetries, common sense reasoning, ambiguous natural language, and statistical modeling. Secondly and more importantly, this is another evidence we are in a completely new AI era in which machines can and are scaling knowledge.
These LLMs have caused a deep shift: we went from attempting to encode human-distilled insights into machines to delegating the learning process itself to machines. AI is ushering in a world in which decisions are made in three primary ways: by humans (which is familiar), by machines (which is becoming familiar), and by collaboration between humans and machines (which is not only unfamiliar but also unprecedented). We will begin to give AI fewer specific instructions about how exactly to achieve the goals we assign it. Much more frequently we will present AI with ambiguos goals and ask: “How, based on your conclusions, should we proceed?”
AI promises to transform all realms of human experience. And the core of its transformations will ultimately occur at the philosophical level, transforming how humans understand reality and our roles within it. In an age in which machines increasingly perform tasks only humans used to be capable of: what, then, will constitute our identity as human beings?
With the rise of AI, the definition of the human role, human aspirations, and human fulfillment will change. For humans accustomed to monopoly on complex intelligence, AI will challenge self-perception. To make sense of our place in this world, our emphasis may need to shift from the centrality of human reason to the centrality of human dignity and autonomy. Human-AI collaboration does not occur between peers. Our task will be to understand the transformations that AI brings to human experience, the challenges it presents to human identity, and which aspects of these developments require regulation or counterbalancing by other human commitments.
The AI revolution has come to stay. Unless we develop new concepts to explain, interpret, and organize its consequent transformations, we will be unprepared to navigate them. We must rely on our most solid resources -reason, moral and ethical values, tradition…- to adapt our relationship with reality so it keeps on being human.