Curtailing Hallucinations in Large Language Models
Posted: December 9th, 2023 | Author: Domingo | Filed under: Artificial Intelligence | Tags: AI, artificial intelligence, Large Language Models, RAG, Retrieval-Augmented Generation | Comments Off on Curtailing Hallucinations in Large Language ModelsIn 2020 Meta (then known as Facebook) published the paper Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, which came up with a framework called retrieval-augmented generation (RAG) to give LLMs access to information beyond their training data.
Large language models can be inconsistent. Sometimes they can grant a perfect answer to a question, but other times they regurgitate aleatory facts from their training data.
Retrieval-augmented generation (RAG) is a technique for enhancing the accuracy and reliability of generative AI models with facts fetched from external sources. In other words, it fills a gap in how LLMs work. Under the hood, LLMs are neural networks, typically measured by how many parameters they contain. An LLM’s parameters essentially represent the general patterns of how humans use words to form sentences. That deep understanding makes LLMs useful in responding to general prompts extremely fast. Nonetheless, it does not serve users who want a deeper dive into a current or more specific topic. Retrieval-augmented generation (RAG) gives models sources they can cite, so users can check any claims. That builds trust. What’s more, the technique can help models clear up ambiguity in a user query.
The roots of the technique go back at least to the early 1970s. That’s when researchers in information retrieval (IR) prototyped what they called question-answering systems, apps that use natural language processing to access text initially in narrow topics.
Implementing RAG in an LLM-based question answering system has two main benefits: It ensures that the model has access to the most current, reliable facts, and that users have access to the model’s sources, ensuring that the accuracy of responses can be easily checked.
By grounding an LLM on a set of external, verifiable facts, the model has fewer opportunities to “hallucinate” or mislead information. RAG allows LLMs to build on a specialized body of knowledge to answer questions in more accurate way. It also reduces the need for users to continuously train the model on new data and update its parameters, as circumstances evolve. In this way, RAG can lower the computational and financial costs of running LLM-powered chatbots in an enterprise setting.
RAG has two phases: retrieval and content generation. In the retrieval phase, algorithms search for and retrieve snippets of information relevant to the user’s prompt or question. In an open-domain, consumer setting, those facts can come from indexed documents on the internet; in a closed-domain, enterprise setting, a narrower set of sources are typically used for added security and reliability.
This collection of outside information is sent to the language model along with the user’s request. During the generative phase, the LLM creates an appealing answer that is customized for the user currently using the enhanced prompt and its internal representation of its training data. A chatbot can then be given the response together with connections to its original sources. The entire procedure can be represented graphically as follows:
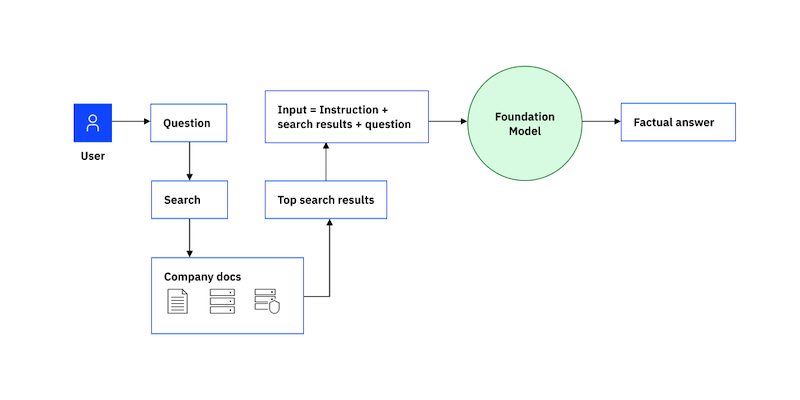
Summing up, customer queries are not always straightforward. They can be ambiguously worded, complex, or require knowledge the model either doesn’t have or can’t easily parse. These are the conditions in which LLMs are prone to making things up. LLMs need to be explicitly trained to recognize questions they can’t answer, it may need though to see thousands of examples of questions that can and can’t be answered. Only then can the model learn to identify an unanswerable question, and probe for more detail until it hits on a question that it has the information to answer. RAG is currently the best-known tool for grounding LLMs on the latest, verifiable information, and it allows LLMs to go one step further by greatly reducing the need to feed and retrain the model on fresh examples.